


ziplist
为什么需要 ziplist?
由于 Redis 是一个内存型数据库,因此在使用相应的数据结构时需要1)节省内存空间,2)提高操作效率。传统的包含指向相邻节点指针的双向链表中在内存使用和操作效率上存在一些问题:
- 存储指针需要额外的内存空间,且该空间在指定硬件平台上是固定的。当存储的数据长度较小时,指针占用空间甚至会超过数据占用空间。
- 传统双向链表中相邻节点在内存中并不连续,这虽然利用了碎片化的内存空间,但是由于增加了一次额外的指针索引,遍历效率低。
ziplist 是 Redis 中设计的一种内存紧凑型的数据结构,可以用来代替传统的双向链表结构。ziplist 使用一块连续的内存空间,通过在每个节点中存储当前及前一个节点的长度来实现双向遍历,节省内存空间,操作效率高。
ziplist 是什么?
下面给出了压缩列表的结构示意图,包括 10byte 的表头元数据,若干个列表节点以及最后的 1byte 的结束标识符。
| zlbytes | zltail | zllen | entry1 | entry2 | ... | entryN | zlend |
# 各部分说明
zlbytes: 整个压缩列表占用的字节数,uint32_t(4byte)
zltail: 压缩列表表尾节点距离压缩列表的起始地址有多少字节,uint32_t(4byte)
zllen: 压缩列表包含的节点数,uint16_t(2byte),当该属性值为 UINT16_MAX 时,真实节点数量需要遍历整个压缩列表才能得到
entry: 压缩列表节点
zlend: 用于标记压缩列表末端的特殊值(0xFF),1byte每个压缩列表的节点中存储的内容可以看作一个字节数组或者整数值,每个节点包含以下三部分内容:
| previous_entry_length | encoding | content |
# 各部分说明
previous_entry_length: 记录前一个节点的长度,长度为 1byte 或 5byte
- 前一个节点长度小于 254 字节时,previous_entry_length 长度为 1 字节,记录前一个节点的长度
- 前一个节点长度大于等于 254 字节时,previous_entry_length 长度为 5 字节,其中第一个字节设置为 0xFE,后面的四个字节用于记录前一个节点长度
encoding: 记录节点的 content 中所保存数据的类型和长度
- 一字节(00开头)、两字节(01开头)或五字节(10开头)的表示字节数组编码,去除最高两位之后的其他位是字节数组长度
- 一字节长(11开头)的表示整数编码,去除最高两位后的其他位可以用于标识整数的类型和位宽
content: 节点值,可以是一个字节数组或者整数值,由 encoding 属性决定ziplist 有什么问题?
前面提到 ziplist 通过使用连续的内存块和精心设计的编码格式来保存列表数据,并实现双向检索的功能。但是,使用 ziplist 仍然存在一些缺点:
- 遍历复杂度高。ziplist 中记录了尾部节点的偏移,可以快速定位到第一个和最后一个节点,同时通过在每个节点中编码节点本身以及前一个节点的字节数,可以实现前向和后向的遍历。但是,当需要查找中间的元素时,就需要从头部后从尾部遍历,复杂度为 O(n);
- 内存重分配。由于 ziplist 使用的是一整块内存,因此在插入或者更新节点时,需要重新结算使用的内存块大小并重新分配内存。特别地,由于节点中存储了前一个节点的长度 previous_entry_length,而该属性是会发生变化的,可能会引发后续的节点依次更新导致 ”连锁更新“ 问题。
针对遍历复杂度高的问题,Redis 在配置文件 redis.conf 中提供了相应参数,用来约束 Hash 和 Zset 结构使用 ziplist 存储时的元素个数以及最大的元素大小,如下所示。例如,在 hash 中元素不超过 512 个,每个元素大小不超过 64byte 时,使用 ziplist 来存储 hash。
hash-max-ziplist-entries 512
hash-max-ziplist-value 64
zset-max-ziplist-entries 128
zset-max-ziplist-value 64连锁更新
前面我们提到 ziplist 中每个节点中使用 previous_entry_length 保存了前一个节点的长度,当插入、更新或者删除节点时,除了修改节点本身,还需要更新该节点的下一个节点的 previous_entry_length。但是,previous_entry_length 本身并不是定长的,会随着前一个节点的长度发生变化。
考虑下面这种情况,e1 到 eN 的所有节点长度都介于 250 到 253 字节之间,此时 previous_entry_length 只需要使用 1 字节的长度。
| zlbytes | zltail | zllen | e1 | e2 | e3 | ... | eN | zlend | 此时,我们将一个长度为 254 的新节点设置为压缩列表的头节点,此时 e1 中的 previous_entry_length 需要使用 5 字节存储前一个节点的长度。e1 修改完成后其节点长度大于等于 254 字节,需要进一步修改 e2 节点。e2 节点修改后会出现同样的问题,需要连续修改列表节点直至最后一个 eN 节点。
| zlbytes | zltail | zllen | new | e1 | e2 | e3 | ... | eN | zlend | 由于更新节点时需要重新分配内存空间,复杂度为 O(N),而连锁更新最坏情况下可能会引发所有节点的更新,复杂度为 O(N^2)。不过考虑到需要连续多个长度介于 250 到 253 字节的节点才有可能发生连续更新,实际出现的概率很低,但是发生时的更新代价较高。
quicklist
为什么需要 quicklist?
在 Redis 早期版本中,使用压缩列表(ziplist)和双向链表来作为 List 的底层实现。当元素个数较少且元素长度较小时,使用压缩列表作为其底层存储;否则使用双向链表作为底层存储结构。
ziplist 使用连续的存储空间,通过精心设计的存储格式有效节省存储空间。但是当元素个数比较多时,修改元素需要重新分配内存空间,影响 Redis 的执行效率,故而选择普通的双向链表。
quicklist 是什么?
quicklist 是 Redis 3.2 版本中新引入的数据结构,在时间和空间效率上实现了较好的折中。Redis 中对于 quicklist 的注释为 A doubly linked list of ziplists,即一个双向链表,每个链表节点都是一个 ziplist。
如下图所示,quicklist 结构中 head 和 tail 是指向首尾节点的指针,count 是 quicklist 中的元素总数(即所有 ziplist 元素个数之和),len 是 quicklist node 的个数,fill 用于指明每个节点中 ziplist 的长度(为正数时表示最多含有的数据项数,为负数时用于表示 ziplist 节点最大的大小,-1 到 -5 分别表示 4KB 到 64 KB)。
当 quicklist 中节点个数较多时,由于我们经常访问的是两端的数据,为了进一步节省空间,Redis 允许对中间的节点进行压缩,compress 参数用于指定两端各有 compress 个节点不压缩。
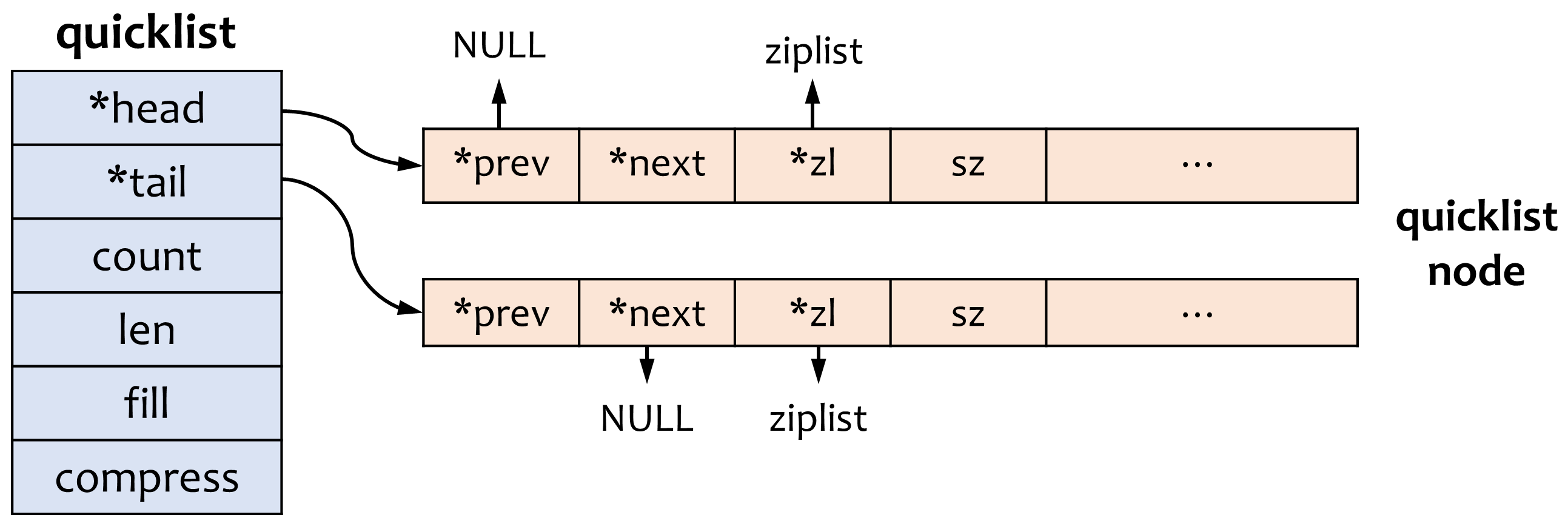
下面给出了 quicklist 中节点的大小及各数据项的含义:
typedef struct quicklistNode {
struct quicklistNode *prev;
struct quicklistNode *next;
unsigned char *zl;
unsigned int sz; /* ziplist size in bytes */
unsigned int count : 16; /* count of items in ziplist */
unsigned int encoding : 2; /* RAW==1 or LZF==2 */
unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */
unsigned int recompress : 1; /* was this node previous compressed? */
unsigned int attempted_compress : 1; /* node can't compress; too small */
unsigned int extra : 10; /* more bits to steal for future usage */
} quicklistNode;More about quicklist
quicklist 通常在每个节点中的 ziplist 最大大小为 8KB 时可以提供最佳性能,可以参考以下资料:
listpack
为什么需要listpack?
Redis 作者提到原有的 ziplist 实现了很好的内存利用优化,同时支持双向遍历,但是在实际使用中除了级联更新外,还可能出现一些问题,因此进一步设计了 listpack 数据结构。
Redis 官方对于 listpack 的解释为 A lists of strings serialization format,即一个字符串列表的序列化格式。Redis 5.0 版本引入了 listpack,最初用做 Stream 类型的底层实现,直到 Redis 7.0 版本中才完全替代 ziplist。
listpack是什么?
下面给出了 listpack 的数据结构,主要由四部分组成,包括 6byte 的表头元数据,若干个列表节点以及最后的 1byte 的结束标识符。
| tot-bytes | num-elements | e1 | e2 | ... | eN | listpack-end-byte |
# 各部分说明
Total bytes:整个 listpack 的空间大小,占用 4 个字节
Num of elements:listpack 中的 entry 个数,占用 2 个字节。当 entry 个数大于等于 65535 时该元素设置为 65535,此时元素个数需要通过遍历得到
Entry:具体元素
End byte:listpack 结束标志,占用 1 个字节,内容为 0xFF。每个 listpack 节点的内容如下,通过精心设计的 element len 字段保存每个 entry 自身的长度,支持前向和后向遍历,从而避免了节点更新时的连锁更新问题。
| encoding-type | element-data | element-tot-len |
# 各部分说明
encoding-type:元素的编码类型
element-data:实际存储的数据,可能为空,因为部分小的元素可以直接存储在 type 中
element-tot-len:encoding 和 data 的长度之和,占用字节数小于等于 5
- element-tot-len 所占用的每个字节的第一个 bit 用于标识;0代表左侧已没有更多字节,1代表左侧还有字节,每个字节只有7 bit 有效。
- element-tot-len 主要用于从后向前遍历,当需要找到当前元素的上一个元素时,可以从后向前依次查找每个字节,直至找到结束的字节确定上一个 entry 的长度。TODO
- ziplist / quicklist / listpack 源码阅读
- ziplist / listpack 优缺点对比
参考资料
- 《Redis设计与实现》Ch7
- 《Redis 5设计与源码分析》
- listpack官方介绍
- 深入分析redis之listpack,取代ziplist?
- 从ziplist到quicklist,再到listpack的启发
- 【Redis】ziplist与listpack源码剖析:Redis数据存储的演进与优化
生总nb