


Neutrams: NEUTRAMS: Neural Network Transformation and Co-design under Neuromorphic Hardware Constraints
开源代码地址:https://github.com/hoangt/neutrams
使用芯片:TianJi,Prime
优化指标:Crossbar之间的脉冲通信量
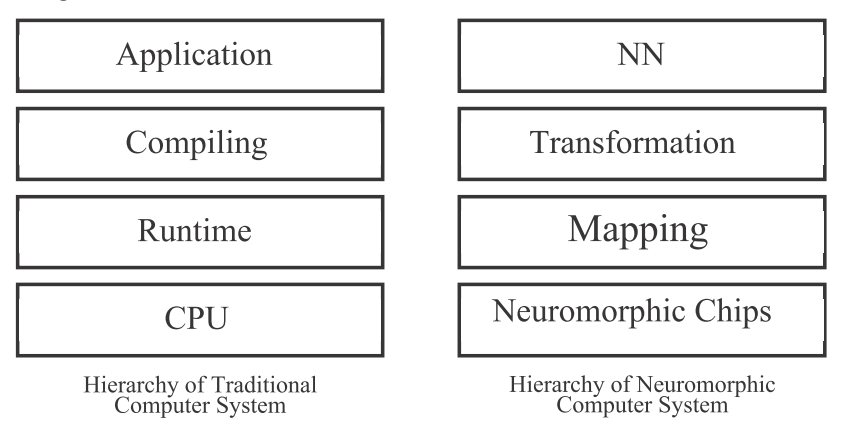
实现步骤:
1. 神经网络表示
类似其他模拟器中常用的方式,将神经网络看成神经元分组和神经元分组之间的连接组成。神经元分组之间都认为使用全连接,不存在的边认为使用权重为0的虚拟边。
2. Training-based transformation(神经网络训练&神经元分组)
a. 使用BP算法训练神经网络
b. 连接稀疏化,通过交换矩阵的行或列来将连接矩阵转换为满足crossbar大小限制的多个子矩阵,并将其余连接权重置为0,目标是最大化剩余的原有连接的绝对值权重之和。
c. 权重量化,将原有的浮点数权重量化为低精度权重,同时使用BP算法微调模型(BP算法中仍然使用浮点数计算)。
d. 在原有的两层中间插入新的全连接层,对于大小为m和n的两个层之间的连接,插入$ \frac{m+n}{2} $的全连接层,重新训练后减少准确度的损失。
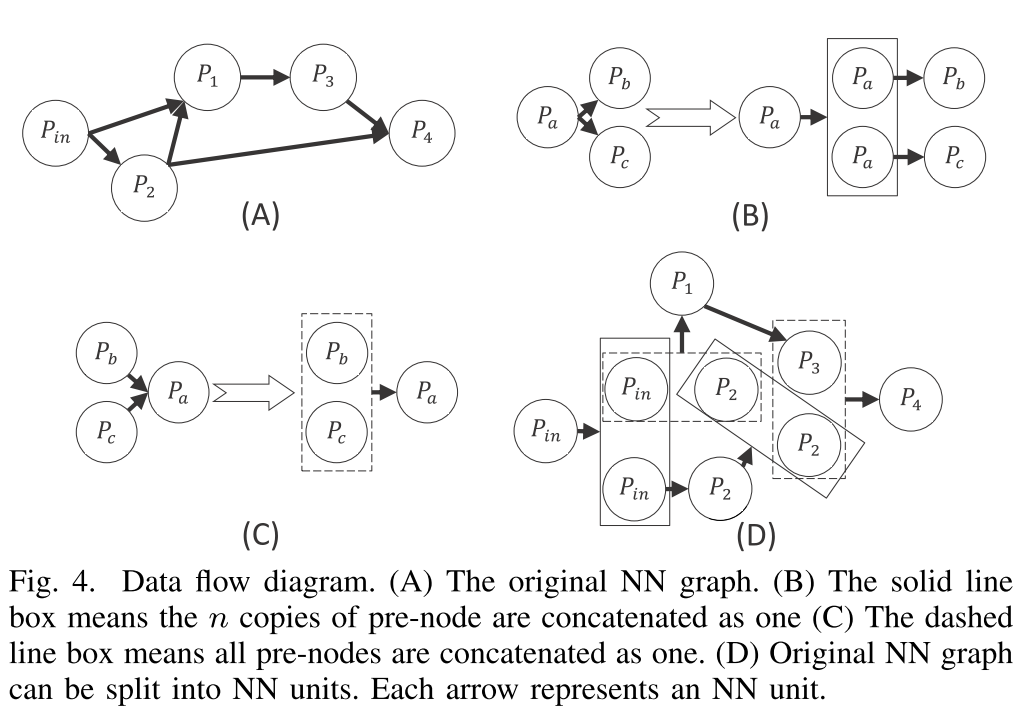
e. 对于复杂的神经网络(非顺序连接的/循环的):对于复杂的神经网络,可以通过图2所示的复制和合并的方式,逐层训练神经元分组之间的突触连接;对于循环神经网络,脉冲神经网络需要将循环连接暂时删除,然后记录循环连接中的信息,将上一时刻信息送入连接后神经元并保存当前时刻连接前神经元送入的信息。
3. Mapping
使用Kernighan-Lin(KL)算法进行神经元子块到crossbar上的映射,目标是最小化crossbar之间的脉冲通信量。
4. Cycle-accurate simulator
实验
1. 考察指标:错误率,能量消耗,芯片有效速度(反比于每个仿真周期内的芯片时钟周期数,芯片有效速度的最大值对应于超过该值部分脉冲无法在一个仿真周期内到达目标神经元)。
2. 结论
a. 插入新的全连接层精度损失低于扩展crossbar规模,插入新的全连接层会增加能量损失、降低有效速度;
b. 基于已训练的前神经元节点训练后节点可以避免误差的积累;
c. 连接稀疏化对于精度影响较大,但是后续可以通过微调网络改善;
d. 部分神经元参数可以同步变大或减小,而不影响最终的输出;
e. 网络规模越大,芯片有效速度越小。
评论 (0)