


SentryOS: Design of Many-Core Big Little µBrains for Energy-Efficient Embedded Neuromorphic Computing
开源地址: 暂无
使用芯片: µBrain
优化指标: 芯片使用面积和功耗
在uBrain神经形态核心上拓展实现的神经形态系统(基于分段总线)和映射框架(SentryOS)。
- 使用分段总线,实现核心之间的一对一互联(实际根据运行数据存在分时复用);
- 基于异构大小核,大网络分割后的子网络规模不同,使用异构大小核来减少uBrain核心中的硬件空闲率
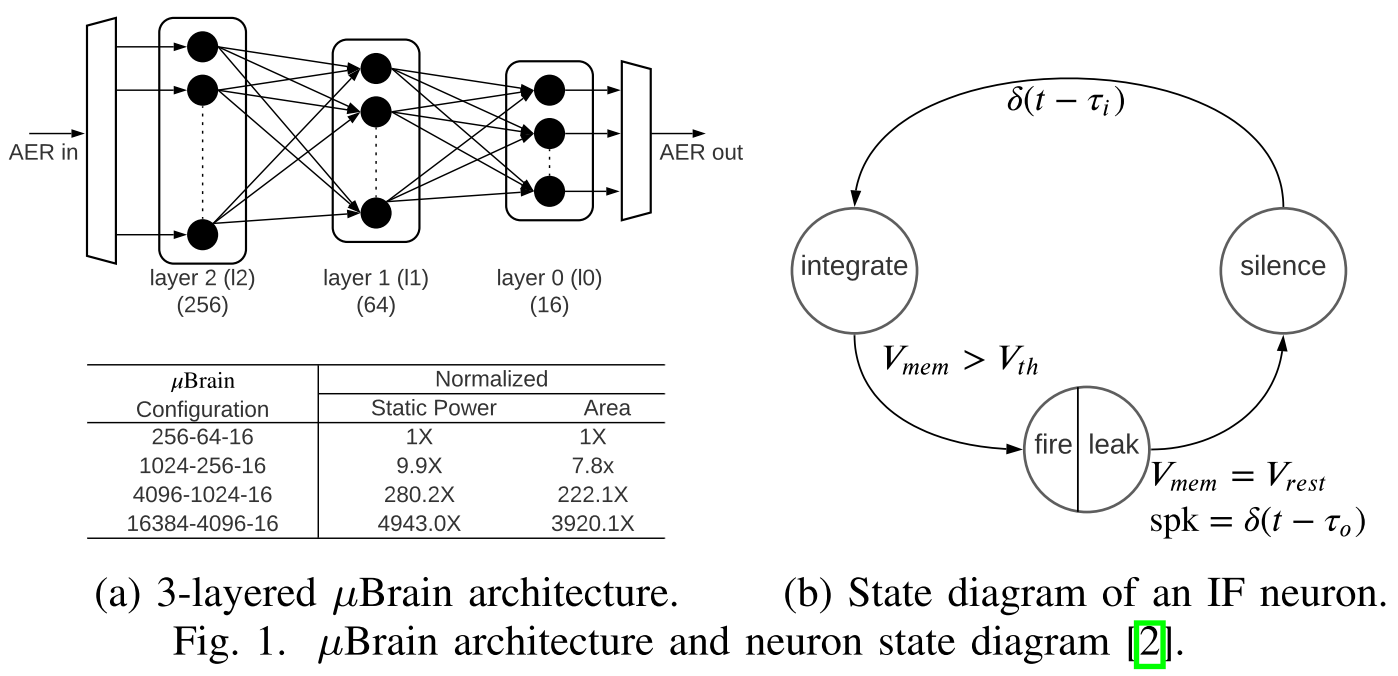
- 异构大小核设计
根据uBrain中使用的三层全连接结构,作者分析了LeNet、AlextNet、VGGNet、ResNet和DenseNet五种模型中L1和L2 neighbors 的数目,发现对于不同应用差别较大,因此使用异构的不同大小的uBrain核心可以提高硬件资源(神经元和突触连接)的利用率。
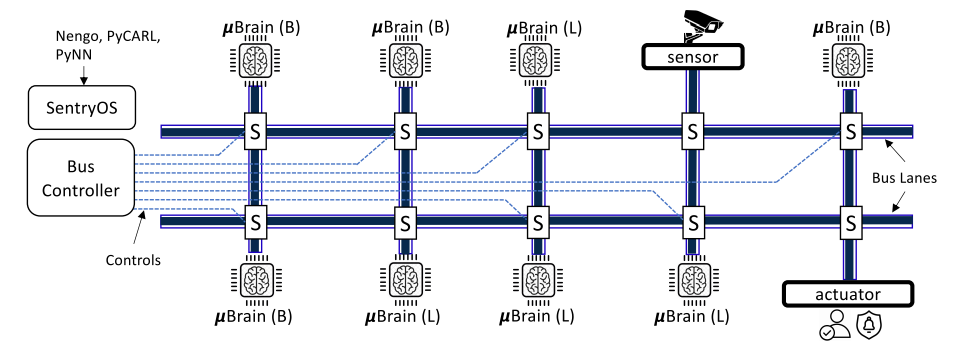
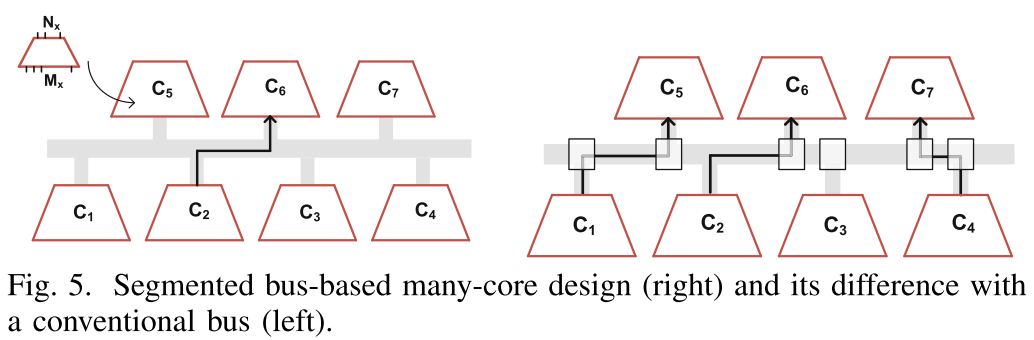
分段总线互联
文中使用分段总线连接不同的uBrain核心来完成通信,相较于传统的共享式的总线结构,分段式总线结构可以价格总线分段,不同段之间可以并行通信,互不影响。为了实现同一时刻所有核心之间可以并行通信,需要多条并行总线,基于训练数据获取到同一时刻最大的并行通行量,从而可以确定所需要的最小的并行总线数目。
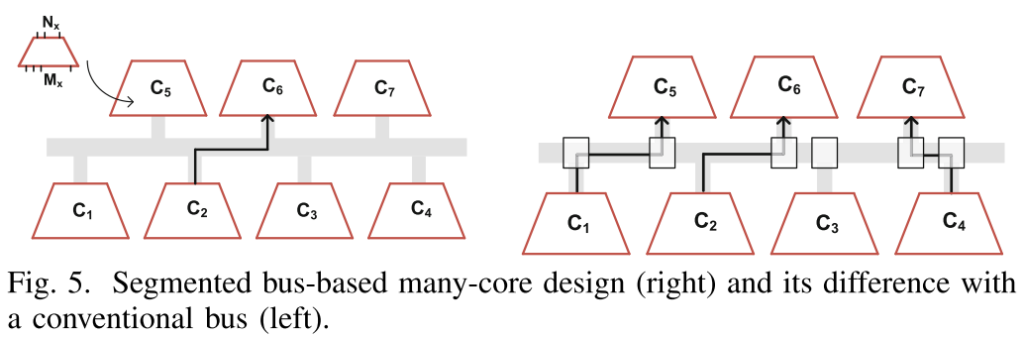
SentryOS设计
a. SentryC编译器
将大网络分割成多个可以映射到uBrain核心的子网络,具体的映射算法如下,主要分为四个步骤
i. 对于每个输出神经元,根据神经元到其的最长路径计算两者之间的距离;
ii. 根据第一步算出的距离给神经元添加索引,需要确保所有子网络中的神经元具有连续索引(论文中的阐述)
iii. 将所有距离小于2的神经元形成集合,$ S_0 = {N_j | dist(N_j ) ≤ 2} $,产生一个子网络,剩下的神经元递归组成其他子网络,这一步中可能会插入权重为1的神经元(调整阈值每来一个脉冲就发放一个脉冲?);
iv. 融合两个子网络$ S_i $ 和$ S_j $ 当且仅当
$$Area(S_i,j) \lt Area(S_i) + Area(S_j)$$
$$Power(S_i,j)\lt Power(S_i)+ Power(S_j)$$
文中提到可以将SentryOS的方案扩展到基于crossbar的神经形态硬件上,即认为crossbar为两层全连接结构(uBrain是三层)

b. SentryRT运行时
类似于DFSynthesizer,使用Max-Plus Algebras的方式确定自网络之间的执行顺序,这篇文章在DFSynthesizer上进一步改善,一方面使用多流水线来执行一个网络,另一方面使用Batch依次运算多个输入图片提高吞吐量。
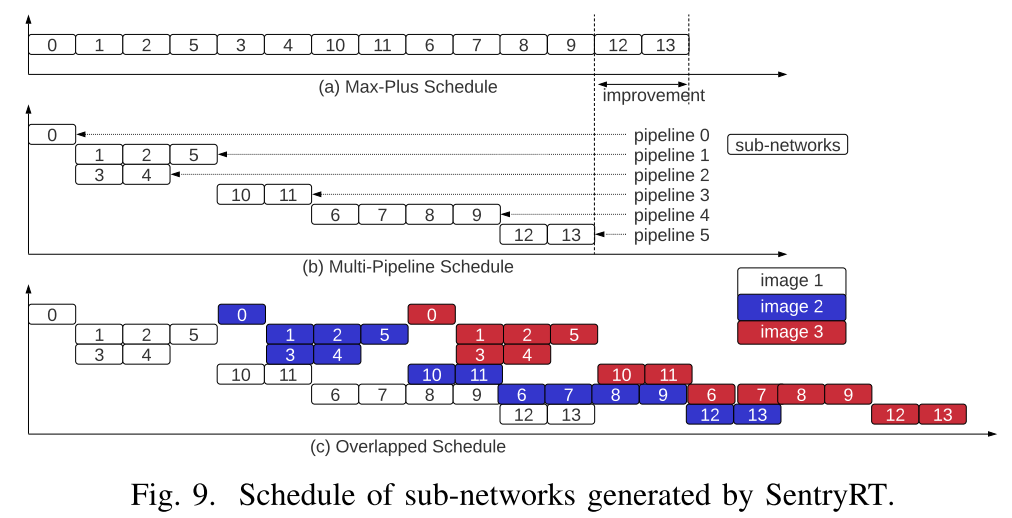
实验评估
a. 使用异构大小核设计可以提高突触等资源的利用率,降低能量消耗,提高吞吐量;
b. 使用分段总线可以避免运行整段总线,同时基于训练数据最小化了总线数目,降低了能量消耗;另一方面,uBrain核心之间通信不再需要路由算法,在映射时所有的通信方案已经确定,减少了通信的延迟。

评论 (0)