标签搜索


搜索到
32
篇与
的结果
-
 SNN & NoC仿真器收集 NoC仿真器NoC(Network on chip)是连接同构或者异构多核心的重要的系统互联结构,NoC仿真器提供了对NoC中多种性能指标的仿真。下面这篇博客中列出了常用的开源NoC仿真器,https://networkonchip.wordpress.com/2011/02/22/simulators/ ,目前了解到最常用的两种分别是noxim,基于SystemC语言开发,修改和添加新功能较为灵活。开源地址:https://github.com/davidepatti/noximbooksim,基于C++语言开发,是 Principles and Practices of Interconnection Networks 这本书的配套教程。开源地址:https://github.com/booksim/booksim,https://github.com/booksim/booksim2SNN仿真器SNN是第三代人工神经网络,基于脉冲传递数据和信息,由于SNN本身具有稀疏性(连接稀疏性和脉冲稀疏性),因此有许多神经形态硬件(Loihi、SpiNNaker、TianjiC、Darwin等)被开发出来用于SNN加速。这里主要列出一些在通用的CPU和GPU平台上进行SNN加速的一些SNN仿真器。NEST,可以用于SNN网络信息处理,网络活动动态、学习和突触可塑性等开源地址:https://github.com/nest/nest-simulator/Brain2,时钟驱动的SNN仿真器开源地址:https://github.com/brian-team/brian2GeNN,GPU加速的SNN仿真器开源地址:https://github.com/genn-team/gennCarlsim,GPU加速的SNN仿真器开源地址:https://github.com/UCI-CARL/CARLsim6Auryn,RSNN仿真器开源地址:https://github.com/fzenke/aurynANNarchy开源地址:https://github.com/ANNarchy/ANNarchySpike, GPU加速的SNN仿真器开源地址:https://github.com/nasiryahm/SpikeSpice,多GPU、时钟驱动的SNN仿真器开源地址:https://github.com/denniskb/spiceNengo,基于Python的神经网络仿真开源地址:https://github.com/nengo/nengoBrain2Loihi,基于brain2实现的Loihi模拟器开源地址:https://github.com/sagacitysite/brian2_loihiNeuroSync开源地址:https://github.com/SNU-HPCS/NeuroSyncdynapse-simulator,Dynap-SE1神经形态硬件仿真器开源地址:https://github.com/YigitDemirag/dynapse-simulator待添加
SNN & NoC仿真器收集 NoC仿真器NoC(Network on chip)是连接同构或者异构多核心的重要的系统互联结构,NoC仿真器提供了对NoC中多种性能指标的仿真。下面这篇博客中列出了常用的开源NoC仿真器,https://networkonchip.wordpress.com/2011/02/22/simulators/ ,目前了解到最常用的两种分别是noxim,基于SystemC语言开发,修改和添加新功能较为灵活。开源地址:https://github.com/davidepatti/noximbooksim,基于C++语言开发,是 Principles and Practices of Interconnection Networks 这本书的配套教程。开源地址:https://github.com/booksim/booksim,https://github.com/booksim/booksim2SNN仿真器SNN是第三代人工神经网络,基于脉冲传递数据和信息,由于SNN本身具有稀疏性(连接稀疏性和脉冲稀疏性),因此有许多神经形态硬件(Loihi、SpiNNaker、TianjiC、Darwin等)被开发出来用于SNN加速。这里主要列出一些在通用的CPU和GPU平台上进行SNN加速的一些SNN仿真器。NEST,可以用于SNN网络信息处理,网络活动动态、学习和突触可塑性等开源地址:https://github.com/nest/nest-simulator/Brain2,时钟驱动的SNN仿真器开源地址:https://github.com/brian-team/brian2GeNN,GPU加速的SNN仿真器开源地址:https://github.com/genn-team/gennCarlsim,GPU加速的SNN仿真器开源地址:https://github.com/UCI-CARL/CARLsim6Auryn,RSNN仿真器开源地址:https://github.com/fzenke/aurynANNarchy开源地址:https://github.com/ANNarchy/ANNarchySpike, GPU加速的SNN仿真器开源地址:https://github.com/nasiryahm/SpikeSpice,多GPU、时钟驱动的SNN仿真器开源地址:https://github.com/denniskb/spiceNengo,基于Python的神经网络仿真开源地址:https://github.com/nengo/nengoBrain2Loihi,基于brain2实现的Loihi模拟器开源地址:https://github.com/sagacitysite/brian2_loihiNeuroSync开源地址:https://github.com/SNU-HPCS/NeuroSyncdynapse-simulator,Dynap-SE1神经形态硬件仿真器开源地址:https://github.com/YigitDemirag/dynapse-simulator待添加 -
Makefile使用学习 参考教程原文:https://makefiletutorial.com/ 中文翻译:https://makefiletutorial.vercel.appMakefile常用内容本文主要基于以上教程记录一些平时阅读Makefile可能会用到的信息。Makefile基础使用首先,Makefile用于帮助决定一个大型程序的哪些部分需要重新编译,如果有任何文件的依赖项发生改变,那么该文件将会重新编译。Makefile通常由一组规则组成,规则通常如下所示:target: prerequisites command command command target是文件名,以空格分隔,通常每个规则只有一个。 command通常是用于制作目标的一系列步骤,需要以制表符Tab而不是空格开头。 prerequisites也是文件名,称为依赖项,以空格分隔,在运行针对目标的命令之前,这些文件需要存在。 下面是一个Makefile的实例:blah: blah.o gcc blah.o -o blah # Runs third blah.o: blah.c gcc -c blah.c -o blah.o # Runs second # Typically blah.c would already exist, but I want to limit any additional required files blah.c: echo "int main() { return 0; }" > blah.c # Runs first 使用make时默认会执行第一个目标blah,或者可以指定目标进行生成make blah。上面的Makefile在执行make指令后按照一系列步骤进行调用: - make选择目标blah,因为第一个目标是默认目标 - blah需要blah.o,所以搜索blah.o目标 - blah.o需要blah.c,所以搜索blah.c目标 - blah.c没有依赖关系,所以echo命令运行 - 然后运行该gcc -c命令,因为所有blah.o依赖项都已完成 - gcc运行top命令,因为所有的blah依赖都跑完了 - 就是这样:blah是一个编译好的c程序Makefile使用文件系统时间戳来判断上次编译以来的先决条件是否发生了变化。例如,如果运行上面的Makefile后删除blah.c,那么三个目标都会被重新执行;如果只是编辑blah.c,那么只有前两个目标会被重新执行;如果只是通过touch blah.o更新blah.o的时间戳,那么只有第一个目标会被重新执行;如果不做任何更改,那么所有目标都不会被执行。需要注意的是,时间戳并不总是有效,例如,您可以修改一个文件,然后将该文件的修改时间戳更改为旧的时间戳。如果你这样做了,make会错误地猜测文件没有改变,因此可以被忽略。全部目标和多个目标如果有多个目标并希望所有目标都被执行,那么可以使用一个all目标,如下所示all: one two three one: touch one two: touch two three: touch three clean: rm -f one two three 当规则有多个目标时,将为每个目标都运行命令,如下所示,其中$@是包含目标名称的自动变量all: f1.o f2.o f1.o f2.o: echo $@ # Equivalent to: # f1.o: # echo f1.o # f2.o: # echo f2.o 自动变量和通配符*通配符在Makefile中*和%是通配符,但它们的含义完全不同。*在文件系统中搜索匹配的文件名。*使用时最好包装在wildcard函数中,如下所示:# Print out file information about every .c file print: $(wildcard *.c) ls -la $? *不可以直接用在变量定义中,当*没有匹配到文件时如果没有使用wildcard函数包装,会直接保持原样。thing_wrong := *.o # Don't do this! '*' will not get expanded thing_right := $(wildcard *.o) all: one two three four # Fails, because $(thing_wrong) is the string "*.o" one: $(thing_wrong) # Stays as *.o if there are no files that match this pattern :( two: *.o # Works as you would expect! In this case, it does nothing. three: $(thing_right) # Same as rule three four: $(wildcard *.o) %通配符%通配符通常在多种情况下使用: - 在"匹配"模式下,它匹配一个或多个字符,这种匹配称为stem。 - 在"替换"模式下,它使用匹配到的stem并在字符串中进行替换。 - %最常用于规则定义和某些特定函数中规则隐式规则 编译C程序:基于n.c生成n.o,使用命令$(CC) -c $(CPPFLAGS) $(CFLAGS) $^ -o $@。 编译C++程序,基于n.cc或n.cpp生成n.o,使用命令$(CXX) -c $(CPPFLAGS) $(CXXFLAGS) $^ -o $@。 链接单个目标文件:基于n.o生成n,使用命令$(CC) $(LDFLAGS) $^ $(LOADLIBES) $(LDLIBS) -o $@。 使用到的变量为 CC:编译C程序的程序;默认cc CXX:编译C++程序的程序;默认g++ CFLAGS: 给 C 编译器的额外标志 CXXFLAGS: 提供给 C++ 编译器的额外标志 CPPFLAGS: 提供给 C 预处理器的额外标志 LDFLAGS: 在编译器应该调用链接器时提供给编译器的额外标志 基于隐式规则可以编译C/C++程序而不用显式地告诉make怎么做。 TO DO后续有时间会添加关于更多规则以及变量与函数,还有命令的相关内容。
-
GDB调试学习 前言使用linux进行systemc的开发时经常出现core dump的文件,对于较大的项目vscode无法很快地进行debug,clion对makefile的支持不是很好,此时想到使用gdb进行调试并学习了一些基本的操作。以下的内容主要参考这篇博客和gdb debug的参考文档。参考资料: 1. https://www.yanbinghu.com/2019/04/20/41283.html 2. Debugging with GDB启动调试GDB需要一个带有调试信息的可执行文件进行调试,因此编译过程中出现的错误无法使用GDB进行排除。通常对于C或者C++程序来说,在编译时加上-g参数可以保留调试信息,否则不能使用GDB进行调试。使用cmake时,可以在CMakeLists.txt文件中添加以下指令以支持GDB调试。SET(CMAKE_BUILD_TYPE "Debug") SET(CMAKE_CXX_FLAGS_DEBUG "$ENV{CXXFLAGS} -O0 -Wall -g2 -ggdb") SET(CMAKE_CXX_FLAGS_RELEASE "$ENV{CXXFLAGS} -O3 -Wall") 如果程序不是自己编译的,那么如何判断文件中是否带有调试信息呢,这篇博客中给出了几种调试的方法。 1. 使用gdb$ gdb main Reading symbols from main... 如果提示no debugging symbols found, 那么不可以使用gdb调试该可执行文件。 2. readelf# main是可执行文件名称 $ readelf -S main | grep debug file查看strip状况 $ file main 如果输出内容为xxx stripped, 那么说明该文件的调试信息已经被去除,不能使用gdb调试。但是not stripped的情况不能说明该文件可以被调试。启动调试无参数程序$ gdb main (gdb) run 输入run命令即可运行程序。有参数程序$ gdb main # world对应参数 (gdb) run world # 使用set args (gdb) set args world (gdb) run 结束调试使用quit指令。调试core文件本文最开始提到进行C++开发时经常遇到core dump的问题,这种情况下需要定位到具体的core dump的位置,目前了解到两种方法,一种是使用backward-cpp插件,在linux系统上可以打印出详细的报错信息,具体可以参考博客https://zhuanlan.zhihu.com/p/397148839;另一种就是利用gdb进行调试。当程序core dump时会产生core文件,可以很大程度上帮助我们定位问题,但是前提是系统没有限制core文件的产生,使用ulimit -c查看$ ulimit -c 0 如果结果是0,那么core dump后也不会有core文件留下,此时需要进行额外的设置ulimit -c unlimied #表示不限制core文件大小 ulimit -c 10 #设置最大大小,单位为块,一块默认为512字节 调试core文件使用如下命令gdb 程序文件名 core文件名 断点设置 & 变量查看关于断点设置和变量查看的相关内容可以查看这篇博客https://www.yanbinghu.com/2019/04/20/41283.html,后续有时间的话会对相关内容加以整理。目前调试主要还是借助IDE,对于一些core dump或者没有IDE的情况,gdb的调试将不可或缺,因此这里简单学习后加以记录。
-
-
常用资源汇总 pythonpip国内镜像# 清华镜像源 https://pypi.tuna.tsinghua.edu.cn/simple # 豆瓣镜像源 http://pypi.douban.com/simple/ # 阿里云镜像源 http://mirrors.aliyun.com/pypi/simple/ # 中国科学技术大学镜像源 http://pypi.mirrors.ustc.edu.cn/simple/ 使用方法为pip install package_name -i 镜像源Ubuntu更换镜像源如果Ubuntu原始速度还可以的话建议不要换源,常用的有阿里云镜像、清华镜像和搜狐镜像,这里是我使用的镜像,北京外国语大学镜像。deb https://mirrors.bfsu.edu.cn/ubuntu/ focal main restricted universe multiverse # deb-src https://mirrors.bfsu.edu.cn/ubuntu/ focal main restricted universe multiverse deb https://mirrors.bfsu.edu.cn/ubuntu/ focal-updates main restricted universe multiverse # deb-src https://mirrors.bfsu.edu.cn/ubuntu/ focal-updates main restricted universe multiverse deb https://mirrors.bfsu.edu.cn/ubuntu/ focal-backports main restricted universe multiverse # deb-src https://mirrors.bfsu.edu.cn/ubuntu/ focal-backports main restricted universe multiverse deb https://mirrors.bfsu.edu.cn/ubuntu/ focal-security main restricted universe multiverse # deb-src https://mirrors.bfsu.edu.cn/ubuntu/ focal-security main restricted universe multiverse # 预发布软件源,不建议启用 # deb https://mirrors.bfsu.edu.cn/ubuntu/ focal-proposed main restricted universe multiverse # deb-src https://mirrors.bfsu.edu.cn/ubuntu/ focal-proposed main restricted universe multiverse Ubuntu换源的具体操作为cd /etc/apt # 将原来的源文件复制一份做备份 sudo cp sources.list sources.list.cpk sudo vim sources.list # 删除全部内容换成上面的镜像网址(具体操作为Esc->:%d->Enter->i进入插入模式->粘贴内容->Esc->:wq) # 保存退出后更新 sudo apt-get update sudo apt-get upgrade WSL2如何可视化窗口借助VcXsvr工具,具体使用方法可以参考网上的教程,如https://zhuanlan.zhihu.com/p/128507562。
-
Cmake常用指令学习 参考教程 Cmake Cookbook:https://www.bookstack.cn/read/CMake-Cookbook/README.md Cmake官方文档:https://cmake.org/cmake/help/latest/guide/tutorial/index.html Cmake入门实战: https://www.hahack.com/codes/cmake/ CMake 生成静态库与动态库:https://blog.csdn.net/zhiyuan2021/article/details/129032343 Cmake介绍Cmake是一种支持跨平台编译的工具,允许通过配置独立的配置文件CMakeList.txt来定制编译流程,随后在不同的平台上进一步生成本地的Makefile和工程文件(Linux平台的Makefile和Windows平台的Visual Studio工程等)。在linux平台下使用Cmake编译程序的主要流程是: 1. 编写CMakeLists.txt; 2. 执行cmake PATH生成Makefile; 3. 执行make编译生成可执行程序或动态/静态链接库。Cmake使用基础案例# CMake 最低版本号要求 cmake_minimum_required (VERSION 2.8) # 项目信息 project (project_name) # 指定生成目标 add_executable(project_name main.cc) CMakeLists.txt的语法由命令、注释和空格组成,命令不区分大小写,#后面的内容是注释。命令由命令名称、小括号和参数组成,参数之间使用空格进行间隔。上面的示例中CmakeLists.txt中使用了几个常用的命令,依次是 1. cmake_minimum_required:指定运行当前配置文件需要的最低的Cmake版本; 2. project:指定项目名称 3. add_executable:将main.cc源文件编译成名为project_name的可执行文件。实际使用中可能有多个源文件,逐个添加源文件是一件非常麻烦的事情,可以使用aux_source_directory命令来获取指定目录下的所有源文件,并将结果存到指定变量名中,使用示例如下:# 查找当前目录下的所有源文件 # 并将名称保存到 DIR_SRCS 变量 aux_source_directory(. DIR_SRCS) # 指定生成目标 add_executable(Demo ${DIR_SRCS}) Cmake生成动态和静态链接库静态和动态链接库的主要目的是为了提供接口供其他程序调用,两者的主要区别在于: 1. 静态链接库的拓展名通常为.a或.lib,在编译时会直接整合到目标程序中,编译成功的可执行文件可以独立运行(不再需要静态库); 2. 动态链接库的拓展名通常为.so或.dll,在编译时不会放到目标程序中,可执行文件无法离开动态链接库单独执行。Cmake用于生成动态和静态链接库的命令为# 动态链接库 add_library(project_name SHARED ${SRC_FILE}) # 静态链接库 add_library(project_name STATIC ${SRC_FILE}) Cmake引用外部库文件Cmake中另外一个常用的使用场景是使用外部库,对于外部库,我们通常需要进行两步操作,即引入头文件和添加链接库,具体示例如下所示:# 引入头文件所在路径 include_directories{include_path} # 添加链接库 target_link_libraries(project_name lib_name) 其他常见的Cmkae命令# 设置C++标准为C++14 set(CMAKE_CXX_STANDARD 14)
-
Latex常用符号记录 参考链接:https://www.cmor-faculty.rice.edu/~heinken/latex/symbols.pdf https://oeis.org/wiki/List_of_LaTeX_mathematical_symbols希腊字母和希伯来字母 Symbol Latex Symbol Latex Symbol Latex $ \alpha $ \alpha $ \nu $ \nu $ \beta $ \beta $ \xi $ \xi $ \gamma $ \gamma $ \omicron $ \omicron $ \delta $ \delta $ \pi $ \pi $ \epsilon $ \epsilon $ \rho $ \varrho $ \zeta $ \zeta $ \sigma $ \sigma $ \eta $ \eta $ \tau $ \tau $ \theta $ \theta $ \upsilon $ \upsilon $ \iota $ \iota $ \phi $ \phi $ \kappa $ \kappa $ \chi $ \chi $ \lambda $ \lambda $ \psi $ \psi $ \mu $ \mu $ \omega $ \omega $ \digamma $ \digamma $ \Delta $ \Delta $ \Gamma $ \Gamma $ \Lambda $ \Lambda $ \Omega $ \Omega $ \phi $ \Phi $ \pi $ \Pi $ \Psi $ \Psi $ \Sigma $ \Sigam $ \Theta $ \Theta $ \Upsilon $ \Upsilon $ \Xi $ \Xi $ \aleph $ \aleph $ \beth $ \beth $ \daleth $ \daleth $ \gimel $ \gimel 关系符和操作符 Symbol Latex Comment Symbol Latex Comment $ < $ < is less than $ > $ > is greater than $ \nless $ \nless is not less than $ \ngtr $ \ngtr is not greater than $ \leq $ \leq is less than or equal to $ \geq $ \geq is greater than or equal to $ \leqslant $ \leqslant is less than or equal to $ \geqslant $ \geqslant is greater than or equal to $ \nleq $ \nleq is neither less than nor equal to $ \ngeq $ \ngeq is neither greater than nor equal to $ \nleqslant $ \nleqslant is neither less than nor equal to $ \ngeqslant $ \ngeqslant is neither greater than nor equal to $ \prec $ \prec precedes $ \succ $ \succ succeeds $ \nprec $ \nprec doesn't precede $ \nsucc $ \nsucc doesn't succeed $ \preceq $ \preceq precedes or equals $ \succeq $ \succeq succeeds or equals $ \npreceq $ \npreceq neither precedes nor equals $ \nsucceq $ \nsucceq neither succeeds nor equals $ \ll $ \ll $ \gg $ \gg $ \lll $ \lll $ \ggg $ \ggg $ \subset $ \subset is a proper subset of $ \supset $ \supset is a proper supset of $ \not\subset $ \not\subset is not a proper subset of $ \not\supset $ \not\supset is not a proper supset of $ \subseteq $ \subseteq is a subset of $ \supseteq $ \supseteq is a supset of $ \nsubseteq $ \nsubseteq is not a subset of $ \nsupseteq $ \nsupseteq is not a supset of $ \sqsubset $ \sqsubset $ \sqsupset $ \sqsupset $ \sqsubseteq $ \sqsubseteq $ \sqsupseteq $ \sqsupseteq $ \parallel $ \parallel is parallel with $ \nparallel $ \nparallel is not parallel with $ \asymp $ \asymp is asymptotic to $ \bowtie $ \bowtie $ \vdash $ \vdash $ \dashv $ \dashv $ \in $ \in is member of $ \ni $ \ni owns, has member of $ \smile $ \smile $ \frown $ \frown $ \models $ \models models $ \notin $ \notin is not member of $ \perp $ \perp is perpendicular with $ \mid $ \mid divides
-
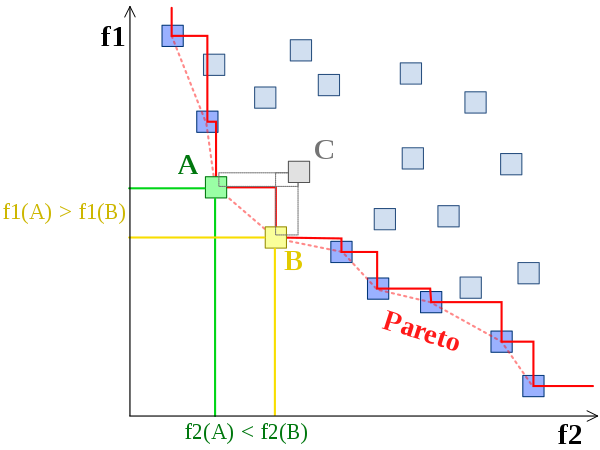
多目标优化问题及两种常用解法 多目标优化问题多目标优化(也称为多目标规划、向量优化、多标准优化、多属性优化或帕累托优化)是多标准决策制定的一个领域,涉及同时优化多个目标函数的数学优化问题,需要在权衡取舍的情况下在两个或多个相互冲突的目标之间做出最佳决策。(维基百科)多目标优化问题中目标函数之间通常相互冲突,求解多目标优化问题通常希望找到可以很好地平衡不同优化目标的解,即帕累托最优解。多目标优化问题的数学描述$$\min_{x\in X} (f_1(x),f_2(x),\dots,f_k(x))$$其中$ k\geq 2 $,$ (f_1(x),f_2(x),\dots,f_k(x)) $式决策函数集合。帕累托最优帕累托最优是指这样一种情况,没有可用的行动或分配可以使一个人过得更好而不会使另一个人过得更糟。多目标优化问题中我们希望找到的就是帕累托最优解,再由决策者决定具体使用那个解。帕累托最优解集指的是所有可行解中的不可支配解集,下面我们将介绍支配和不可支配解集的概念。支配和不可支配解集 当解$ x_1 $和$ x_2 $满足以下两个条件时 * 对于所有的目标函数,$ f_i(x_1)\leq f_i(x_2) $,其中$ 1\leq i \leq k $ * 至少由一个目标函数$ f_i(x) $满足$ f_i(x_1) < f_i(x_2) $,其中$ 1\leq i \leq k $ 我们称$ x_1 $支配$ x_2 $,如上图中$ A $和$ B $都支配$ C $,但彼此之间不存在支配关系。当一个解集中任何一个解都不能被该集合中其他解支配,那么就称该解集为不可支配解集。一组帕累托最优结果,如上图中红色的边界,称为帕累托前沿或帕累托边界。求解多目标优化问题的方法主要分为两类,一种是将多目标优化问题转换成单目标优化问题,常用的方法是对目标函数值加权求和或保留一个目标函数、其余的目标函数被转化为限定条件。但是由于实际应用中目标函数的函数值范围不好确定,因此转换成单目标优化算法的效果常常不好。实际应用更加广泛的是另一种采用多目标的优化算法。多目标粒子群算法MOPSO多目标粒子群算法最早由Coello等人提出[1],算法的大致处理步骤如下所示: 和粒子群算法不同的是,这里添加了支配关系判断的步骤,同时选择全局最优解以及更新个体最优的步骤和粒子群算法也有所不同。此外,MOPSO还额外维护了精英解和解空间的网格,下面我们将分别加以介绍。首先是支配关系的判断,根据第一部分中对于帕累托前沿和支配关系的介绍,我们知道多目标优化问题中解的优劣由支配关系来加以判断。每次迭代开始时,我们需要从精英解集合中选择当前的全局最优解,精英解中包含的是不被其他解支配的解的集合,换言之,精英解包含的是目前获取到的帕累托前沿。选择全局最优解的步骤如下: 1. 在解集空间中绘制网格,即根据当前的解集中不同目标函数的最大值和最小值,将空间均匀等分并给每个子空间添加索引,确定不同的解所对应的子空间。 2. 对于包含解的子空间,判断每个子空间中存在的解个数$ N_1,\cdots,N_k $,使用轮盘赌算法获取当前的全局最优解,轮盘赌的概率和解的个数呈反相关关系(让解稀疏的子空间拥有更大的被选中的概率,设法让解在帕累托前沿上分布更均匀)。选择好当前的全局最优解后更新粒子的位置和速度,更新公式和粒子群算法一致。$$v_i = w \times v_i + c_1\times rand() \times ((p_{best})_i-x_i) + c_2\times rand()\times ((g_{best})_i-x_i)$$粒子更新后会根据粒子当前解和局部最优解之间的支配关系更新粒子的局部最优解。在更新局部最优解之前,还可以采取类似于遗传算法的步骤,以一定的概率对粒子的当前解进行变异。更新完局部最优解之后更新精英解集合,保留当前不被其他解支配的解,同时为了避免精英解过大,可以设置一个阈值来控制精英解集合中的解数目,多余的精英解被随机抛弃。多目标遗传算法NSGA-II多目标遗传算法NSGA-II由Deb等人提出[2],算法的大致处理步骤如下所示: 相较于单目标进化算法添加了快速非支配排序和父代、子代合并操作增加种群多样性,此外从$ rank_i $ 中取出一部分个体有两种方式、一种是拥挤距离排序、另一种是随机选择。下面我们将分别加以介绍。对于当前已有的父代解和子代集合,融合两个集合产生当前的解集合,首先执行非支配排序,非支配排序的大致步骤为,先找出解集中的非支配边沿,将这部分的解的$ rank $置为1;去掉这部分解,继续找出剩下的解集中的非支配边沿,将这部分的解的$ rank $置为2,重复上述步骤知道遍历完所有的解。实际实现中需要记录每个解支配的解,方便后续的$ rank $计算,具体可以参考后面的参考代码实现。在当前解集合中选取下一轮迭代的父代解集合。需要注意的是对于固定大小的父代解集合,这里依次从$ rank=1 $的解开始加入,知道数量满足要求。最后可能需要从$ rank=i $的解集合中选取一部分,此时有两种方式,一种是随机选取,一种是根据拥挤度距离排序后选取。拥挤度距离计算的示意图如下, 拥挤度距离可以用来衡量当前解周围的解的密度,优先选择拥挤度距离大(解稀疏)的地方可以使得最后求得的帕累托前沿上解分布更均匀。对当前的解执行交叉变异操作产生下一轮迭代的子代解,交叉变异操作可以有不同的实现。代码实现目标函数# -*- coding : utf-8 -*- from collections import defaultdict import math import numpy as np def ZDT1(x): """ 测试函数——ZDT1 :parameter :param x: 为 m 维向量,表示个体的具体解向量 :return f: 为两个目标方向上的函数值 """ poplength = len(x) f = defaultdict(float) g = 1 + 9 * sum(x[1:poplength]) / (poplength - 1) f[1] = x[0] f[2] = g * (1 - pow(x[0] / g, 0.5)) return f def ZDT2(x): poplength = len(x) f = defaultdict(float) g = 1 + 9 * sum(x[1:poplength]) / (poplength - 1) f[1] = x[0] f[2] = g * (1 - (x[0] / g) ** 2) return f def KUR(x): f = defaultdict(float) poplength = len(x) f[1] = 0 for i in range(poplength - 1): f[1] = f[1] + (-10) * math.exp((-0.2) * (x[i] ** 2 + x[i+1] ** 2) ** 0.5) for i in range(poplength): f[2] = abs(x[i]) ** 0.8 + 5 * math.sin(x[i] ** 3) return f # 轮盘赌函数 def RouletteWheelSelection(P): idx = np.argsort(P) val = np.sort(P) prob = [_/sum(P) for _ in val] # 概率 dprob = np.cumsum(prob) # 累积概率 seed = np.random.random() # 随机数 res = idx[(dprob>seed).tolist().index(True)] # 选择 return res MOPSO参考了Matlab实现# -*- coding: utf-8 -*- # Lishengxie # 2023-03-03 # Implementation of multi-objective particle swarm algorithm from collections import defaultdict import numpy as np from utils import ZDT1, ZDT2, KUR, RouletteWheelSelection import matplotlib.pyplot as plt import copy class Particle: """ Implementation of particle class, which provides the constraints for particle's position and the method to compute dominance. """ def __init__(self): self.position = None self.velocity = None self.best = None self.cost = defaultdict() self.is_dominated = False def bound_position(self, var_min, var_max): """ 对解向量 solution 中的每个分量进行定义域判断,超过最大值,将其赋值为最大值;小于最小值,赋值为最小值 Args: var_min: 位置域下限 var_max: 位置域上限 Returns: None """ self.position = np.clip(self.position, var_min, var_max) def update_position(self, var_min, var_max): """ Update particle'sposition Args: var_min: 位置域下限 var_max: 位置域上限 Returns: None """ self.position += self.velocity self.bound_position(var_min, var_max) def cal_cost(self, objective_func): """ Calculate the objective scores. Args: objective_func: Function, return objective scores with position given. Return: cost: collection.defaultdict, cost function scores with keys from `1` to `N`. """ return objective_func(self.position) def dominate(self, other): """ Return the dominance relationship between the current particle and input particle. `A` dominates `B` if any of `A`'s cost is less than or equal to `B` and at least one of `A`'s cost is less than `B`. Args: other: Particle, the other particle to be compared """ v1 = np.array(list(self.cost.values())) v2 = np.array(list(other.cost.values())) return (v1<=v2).all() and (v1<v2).any() class MOPSO: """ Multi-objective particle swarm optimization algorithm. """ def __init__(self, max_iter=200, n_pop=200, n_rep=100,\ w=0.5, wdamp=0.99, c1=1., c2=2., n_grid=7, alpha=0.1,\ beta=2., gamma=2., mu=0.1, n_var=5, var_min=0., var_max=1., \ objective_func=ZDT1, objective_num=2): """ Args: max_iter: int, Maximum Number of Iterations n_pop: int, Population Size n_rep: int, Repository Size w: float, Intertia Weight wdamp: float, Intertia Weight Damping Rate c1: float, Personal Learning Coefficient c2: float, Global Learning Coefficient n_grid: int, number of Grids per Dimension alpha: float, Inflation Rate beta: float, Leader Selection Pressure gamma: float, Deletion Selection Pressure mu: float, Mutation Rate n_var: int, Number of decision variables var_max: float, Lower Bound of Variables var_min: float, Upper Bound of Variables objective_func: function, cost function to minimize objective_num: int, number of cost function Returns: None """ self.max_iter = max_iter self.n_pop = n_pop self.n_rep = n_rep self.w = w self.wdamp = wdamp self.c1 = c1 self.c2 = c2 self.n_grid = n_grid self.alpha = alpha self.beta = beta self.gamma = gamma self.mu = mu self.n_var = n_var self.var_max = var_max self.var_min = var_min self.objective_func = objective_func self.objective_num = objective_num # particle swam self.particles = [] # repository, which stores the dominant particles on the Pareto Front self.repository = [] # init particle swam self.init_particle() # grid matrix, avoiding the computation of crowding distance self.grid = np.zeros((self.objective_num, self.n_grid + 2)) self.grid_index = None self.grid_subindex = None def init_particle(self): """ Init particles with the number of `n_pop` """ for i in range(self.n_pop): # init a particle p = Particle() p.position = np.random.random(self.n_var) * (self.var_max-self.var_min) + self.var_min p.velocity = np.zeros(self.n_var) # cost dict p.cost = p.cal_cost(self.objective_func) # local best solution p.best = Particle() p.best.position = p.position p.best.cost = p.cost # add particle to the particle swam self.particles.append(p) def determine_domination(self, pop): """ Determine the dominance relationship in a given group of particles. Args: pop: List[Particle], group of particles """ n_pop = len(pop) # reset all the `is_dominated` be False for i in range(n_pop): pop[i].is_dominated = False # traverse all of the particle pairs for i in range(n_pop-1): for j in range(i+1, n_pop): if pop[i].dominate(pop[j]): pop[j].is_dominated = True if pop[j].dominate(pop[i]): pop[i].is_dominated = True return pop def determine_repository(self, pop): """ Add the particle `p` in `pop` to `repository` if `p` is not been dominated. Args: pop: List[Particle], group of particles """ for i in range(len(pop)): if not pop[i].is_dominated: self.repository.append(copy.deepcopy(pop[i])) def create_grid(self, pop): """ Create grids in cost function space(2D or more), limited by the maximum and minimum value of cost funciton. Args: pop: List[Particle], group of particles """ n_pop = len(pop) cost = np.zeros((self.objective_num, n_pop)) # Get cost of each particle for c in range(1, self.objective_num+1): for i in range(n_pop): cost[c-1][i] = pop[i].cost[c] cmin = np.min(cost, axis=1) cmax = np.max(cost, axis=1) dc = cmax-cmin cmin = cmin - self.alpha * dc; cmax = cmax + self.alpha * dc; for j in range(self.objective_num): self.grid[j] = np.append(np.linspace(cmin[j], cmax[j], self.n_grid+1), np.inf) return cost def find_grid_index(self, pop, cost): """ Find the grid index for each particle in the grids matrix, the multi-dimensional index is transfered to integer. Args: pop: List[Particle], group of particles cost: numpy.ndarray, cost function matrix for particles in `pop`. """ n_pop = len(pop) self.grid_subindex = np.zeros((n_pop, self.objective_num), dtype=np.uint) self.grid_index = np.zeros((n_pop), dtype=np.uint) for i in range(n_pop): for j in range(self.objective_num): self.grid_subindex[i][j] = np.argwhere(self.grid[j] > cost[j][i])[0] if j == 0: self.grid_index[i] = self.grid_subindex[i][j] else: self.grid_index[i] = (self.grid_index[i]-1)*self.n_grid + self.grid_subindex[i][j] def select_leader(self): """ Select a leader from `repository` based on the Roulette algorithm. More about the Roulette algorithm, refer to `https://blog.csdn.net/doubi1/article/details/115923275` """ # occupied cells oc = np.unique(self.grid_index) # number of particles in the occupied cells N = np.zeros_like(oc) for i in range(len(N)): N[i] = np.sum(self.grid_index==oc[i]) P = np.exp(-self.beta*N) P = P/np.sum(P) sel = RouletteWheelSelection(P) # selected cell sc = oc[sel] # selected cell members scm = np.argwhere(self.grid_index==sc).flatten() # selected member sm = scm[np.random.randint(0, len(scm))] return self.repository[sm] def mutate(self, position, pm): """ Select a particle `j`(randomly selected) to conduct mutation. Args: pm: float, mutation scale. """ j = np.random.randint(0, self.n_var) dx = pm * (self.var_max - self.var_min) lb = position[j] - dx if lb < self.var_min: lb = self.var_min ub = position[j] + dx if ub > self.var_max: ub = self.var_max x_new = position x_new[j] = np.random.random() * (ub-lb) + lb return x_new def delete_one_rep_member(self): """ Select a particle from `repository` and delete it. """ # occupied cells oc = np.unique(self.grid_index) # number of particles in the occupied cells N = np.zeros_like(oc) for i in range(len(N)): N[i] = np.sum(self.grid_index==oc[i]) P = np.exp(self.gamma*N) P = P/np.sum(P) sel = RouletteWheelSelection(P) # selected cell sc = oc[sel] # selected cell members scm = np.argwhere(self.grid_index==sc).flatten() # selected member sm = scm[np.random.randint(0, len(scm))] self.repository[sm] = None def plot(self): X = [] Y = [] X2 = [] Y2 = [] for ind in self.particles: X.append(ind.cost[1]) Y.append(ind.cost[2]) for ind in self.repository: X2.append(ind.cost[1]) Y2.append(ind.cost[2]) # plt.xlim(0, 1) # plt.ylim(0, 1) plt.xlabel('F1') plt.ylabel('F2') plt.scatter(X, Y) plt.scatter(X2, Y2) def solve(self): """ Execute the optimization process. """ # Init step self.particles = self.determine_domination(self.particles) self.determine_repository(self.particles) cost = self.create_grid(self.repository) self.find_grid_index(self.repository, cost) # Main loop for it in range(self.max_iter): for i in range(self.n_pop): # select the global best particle leader = self.select_leader() # update particle's velocity and position self.particles[i].velocity = self.w * self.particles[i].velocity \ + self.c1 * np.random.random(self.n_var) * (self.particles[i].best.position - self.particles[i].position) \ + self.c2 * np.random.random(self.n_var) * (leader.position - self.particles[i].position) self.particles[i].update_position(self.var_min, self.var_max) self.particles[i].cost = self.particles[i].cal_cost(self.objective_func) # Apply Mutation pm = (1-(it-1) / (self.max_iter - 1)) ** (1./self.mu) if np.random.random() < pm: new_sol = Particle() new_sol.position = self.mutate(self.particles[i].position, pm) new_sol.cost = new_sol.cal_cost(self.objective_func) if new_sol.dominate(self.particles[i]): self.particles[i].position = new_sol.position self.particles[i].cost = new_sol.cost elif self.particles[i].dominate(new_sol): pass else: if np.random.random() < 0.5: self.particles[i].position = new_sol.position self.particles[i].cost = new_sol.cost # update locate best solution if self.particles[i].dominate(self.particles[i].best): self.particles[i].best.position = self.particles[i].position self.particles[i].best.cost = self.particles[i].cost elif self.particles[i].best.dominate(self.particles[i]): pass else: if np.random.random() < 0.5: self.particles[i].best.position = self.particles[i].position self.particles[i].best.cost = self.particles[i].cost # update `repository` # for each in self.particles: # self.repository.append(each) self.determine_repository(self.particles) self.repository = self.determine_domination(self.repository) tmp = [] for each in self.repository: if not each.is_dominated: tmp.append(each) self.repository = tmp # update cost grid based on `repository` cost = self.create_grid(self.repository) self.find_grid_index(self.repository, cost) # delete particles randomly from `repository` which is out of capacity if len(self.repository) > self.n_rep: for _ in range(len(self.repository) - self.n_rep): self.delete_one_rep_member() # update grid index for the next loop grid_index = [] repository = [] for i in range(len(self.repository)): if self.repository[i] is None: continue else: grid_index.append(self.grid_index[i]) repository.append(self.repository[i]) self.grid_index = grid_index self.repository = repository plt.clf() plt.title('current iteration:' + str(it + 1)) self.plot() plt.pause(0.01) print("Iteration {}: number of rep members = {}".format(it, len(self.repository))) self.w = self.w * self.wdamp plt.show() if __name__ == "__main__": # mopso = MOPSO(objective_func=KUR, var_max=5, var_min=-5, n_var=3, max_iter=400, n_pop=100) mopso = MOPSO(objective_func=ZDT1) mopso.solve() NSGA-II参考了开源实现# -*- coding = utf-8 -*- from collections import defaultdict import numpy as np import random import matplotlib.pyplot as plt import math from utils import ZDT1, ZDT2, KUR class Individual(object): def __init__(self): self.solution = None # 实际赋值中是一个 nparray 类型,方便进行四则运算 self.objective = defaultdict() self.n = 0 # 解p被几个解所支配,是一个数值(左下部分点的个数) self.rank = 0 # 解所在第几层 self.S = [] # 解p支配哪些解,是一个解集合(右上部分点的内容) self.distance = 0 # 拥挤度距离 def bound_process(self, bound_min, bound_max): """ 对解向量 solution 中的每个分量进行定义域判断,超过最大值,将其赋值为最大值;小于最小值,赋值为最小值 :param bound_min: 定义域下限 :param bound_max: 定义域上限 :return: """ for i, item in enumerate(self.solution): if item > bound_max: self.solution[i] = bound_max elif item < bound_min: self.solution[i] = bound_min def calculate_objective(self, objective_fun): self.objective = objective_fun(self.solution) # 重载小于号“<” def __lt__(self, other): v1 = list(self.objective.values()) v2 = list(other.objective.values()) for i in range(len(v1)): if v1[i] > v2[i]: return 0 # 但凡有一个位置是 v1大于v2的 直接返回0,如果相等的话比较下一个目标值 return 1 # 重载大于号“>” def __gt__(self, other): v1 = list(self.objective.values()) v2 = list(other.objective.values()) for i in range(len(v1)): if v1[i] < v2[i]: return 0 # 但凡有一个位置是 v1小于v2的 直接返回0 return 1 class NSGAII: def __init__(self, max_iter=200, n_pop=100, n_var=30,\ eta=1, var_min=0, var_max=1, objective_fun = ZDT1): """ Args: max_iter: int, Maximum Number of Iterations n_pop: int, Population Size eta: float, 变异分布参数,该值越大则产生的后代个体逼近父代的概率越大;Deb建议设为 1 n_var: int, Number of decision variables var_max: float, Lower Bound of Variables var_min: float, Upper Bound of Variables objective_func: function, cost function to minimize Returns: None """ self.max_iter = max_iter self.n_pop = n_pop self.n_var = n_var self.eta = eta self.var_min = var_min self.var_max = var_max self.objective_fun = objective_fun self.P = [] self.init_P() def init_P(self): for i in range(self.n_pop): self.P.append(Individual()) # 随机生成个体可行解 self.P[i].solution = np.random.rand(self.n_var) * (self.var_max - self.var_min) + self.var_min self.P[i].bound_process(self.var_min, self.var_max) # 定义域越界处理 self.P[i].calculate_objective(self.objective_fun) # 计算目标函数值 def fast_non_dominated_sort(self, P): """ 非支配排序 :param P: 种群 P :return F: F=(F_1, F_2, ...) 将种群 P 分为了不同的层, 返回值类型是dict,键为层号,值为 List 类型,存放着该层的个体 """ F = defaultdict(list) for p in P: p.S = [] p.n = 0 for q in P: if p < q: # if p dominate q p.S.append(q) # Add q to the set of solutions dominated by p elif q < p: p.n += 1 # Increment the domination counter of p if p.n == 0: p.rank = 1 F[1].append(p) i = 1 while F[i]: Q = [] for p in F[i]: for q in p.S: q.n = q.n - 1 if q.n == 0: q.rank = i + 1 Q.append(q) i = i + 1 F[i] = Q return F def crowding_distance_assignment(self, L): """ 传进来的参数应该是L = F(i), 类型是List""" l = len(L) # number of solution in for i in range(l): L[i].distance = 0 # initialize distance for m in L[0].objective.keys(): L.sort(key=lambda x: x.objective[m]) # sort using each objective value L[0].distance = float('inf') L[l - 1].distance = float('inf') # so that boundary points are always selected # 排序是由小到大的,所以最大值和最小值分别是 L[l-1] 和 L[0] f_max = L[l - 1].objective[m] f_min = L[0].objective[m] for i in range(1, l - 1): # for all other points L[i].distance = L[i].distance + (L[i + 1].objective[m] - L[i - 1].objective[m]) / (f_max - f_min) # 虽然发生概率较小,但为了防止除0错,当bug发生时请替换为以下代码 # if f_max != f_min: # for i in range(1, l - 1): # for all other points # L[i].distance = L[i].distance + (L[i + 1].objective[m] - L[i - 1].objective[m]) / (f_max - f_min) def binary_tournament(self, ind1, ind2): """ 二元锦标赛 :param ind1:个体1号 :param ind2: 个体2号 :return:返回较优的个体 """ if ind1.rank != ind2.rank: # 如果两个个体有支配关系,即在两个不同的rank中,选择rank小的 return ind1 if ind1.rank < ind2.rank else ind2 elif ind1.distance != ind2.distance: # 如果两个个体rank相同,比较拥挤度距离,选择拥挤读距离大的 return ind1 if ind1.distance > ind2.distance else ind2 else: # 如果rank和拥挤度都相同,返回任意一个都可以 return ind1 def make_new_pop(self, P, eta, bound_min, bound_max, objective_fun): """ use select,crossover and mutation to create a new population Q :param P: 父代种群 :param eta: 变异分布参数,该值越大则产生的后代个体逼近父代的概率越大。Deb建议设为 1 :param bound_min: 定义域下限 :param bound_max: 定义域上限 :param objective_fun: 目标函数 :return Q : 子代种群 """ popnum = len(P) Q = [] # binary tournament selection for i in range(int(popnum / 2)): # 从种群中随机选择两个个体,进行二元锦标赛,选择出一个 parent1 i = random.randint(0, popnum - 1) j = random.randint(0, popnum - 1) parent1 = self.binary_tournament(P[i], P[j]) # 从种群中随机选择两个个体,进行二元锦标赛,选择出一个 parent2 i = random.randint(0, popnum - 1) j = random.randint(0, popnum - 1) parent2 = self.binary_tournament(P[i], P[j]) while (parent1.solution == parent2.solution).all(): # 如果选择到的两个父代完全一样,则重选另一个 i = random.randint(0, popnum - 1) j = random.randint(0, popnum - 1) parent2 = self.binary_tournament(P[i], P[j]) # parent1 和 parent1 进行交叉,变异 产生 2 个子代 Two_offspring = self.crossover_mutation(parent1, parent2, eta, bound_min, bound_max, objective_fun) # 产生的子代进入子代种群 Q.append(Two_offspring[0]) Q.append(Two_offspring[1]) return Q def crossover_mutation(self, parent1, parent2, eta, bound_min, bound_max, objective_fun): """ 交叉方式使用二进制交叉算子(SBX), 变异方式采用多项式变异(PM) :param parent1: 父代1 :param parent2: 父代2 :param eta: 变异分布参数, 该值越大则产生的后代个体逼近父代的概率越大。Deb建议设为 1 :param bound_min: 定义域下限 :param bound_max: 定义域上限 :param objective_fun: 目标函数 :return: 2 个子代 """ poplength = len(parent1.solution) offspring1 = Individual() offspring2 = Individual() offspring1.solution = np.empty(poplength) offspring2.solution = np.empty(poplength) # 二进制交叉 for i in range(poplength): rand = random.random() beta = (rand * 2) ** (1 / (eta + 1)) if rand < 0.5 else (1 / (2 * (1 - rand))) ** (1.0 / (eta + 1)) offspring1.solution[i] = 0.5 * ((1 + beta) * parent1.solution[i] + (1 - beta) * parent2.solution[i]) offspring2.solution[i] = 0.5 * ((1 - beta) * parent1.solution[i] + (1 + beta) * parent2.solution[i]) # 多项式变异 # TODO 变异的时候只变异一个,不要两个都变,不然要么出现早熟现象,要么收敛速度巨慢 why? for i in range(poplength): mu = random.random() delta = 2 * mu ** (1 / (eta + 1)) if mu < 0.5 else (1 - (2 * (1 - mu)) ** (1 / (eta + 1))) offspring1.solution[i] = offspring1.solution[i] + delta # 定义域越界处理 offspring1.bound_process(bound_min, bound_max) offspring2.bound_process(bound_min, bound_max) # 计算目标函数值 offspring1.calculate_objective(objective_fun) offspring2.calculate_objective(objective_fun) return [offspring1, offspring2] def solve(self): # 否 -> 非支配排序 self.fast_non_dominated_sort(self.P) Q = self.make_new_pop(self.P, self.eta, self.var_min, self.var_max, self.objective_fun) P_t = self.P # 当前这一届的父代种群 Q_t = Q # 当前这一届的子代种群 for gen_cur in range(self.max_iter): R_t = P_t + Q_t # combine parent and offspring population F = self.fast_non_dominated_sort(R_t) P_n = [] # 即为P_t+1,表示下一届的父代 i = 1 while len(P_n) + len(F[i]) < self.n_pop: # until the parent population is filled self.crowding_distance_assignment(F[i]) # calculate crowding-distance in F_i P_n = P_n + F[i] # include ith non dominated front in the parent pop i = i + 1 # check the next front for inclusion F[i].sort(key=lambda x: x.distance) # sort in descending order using <n,因为本身就在同一层,所以相当于直接比拥挤距离 P_n = P_n + F[i][:self.n_pop - len(P_n)] Q_n = self.make_new_pop(P_n, self.eta, self.var_min, self.var_max, self.objective_fun) # use selection,crossover and mutation to create a new population Q_n # 求得下一届的父代和子代成为当前届的父代和子代,,进入下一次迭代 《=》 t = t + 1 P_t = P_n Q_t = Q_n # 绘图 plt.clf() plt.title('current generation:' + str(gen_cur + 1)) self.plot_P(P_t) plt.pause(0.1) plt.show() return 0 def plot_P(self, P): """ 假设目标就俩,给个种群绘图 :param P: :return: """ X = [] Y = [] X1 = [] Y1 = [] for ind in P: X.append(ind.objective[1]) Y.append(ind.objective[2]) if ind.rank == 1: X1.append(ind.objective[1]) Y1.append(ind.objective[2]) plt.xlabel('F1') plt.ylabel('F2') plt.scatter(X, Y) plt.scatter(X1, Y1) def show_some_ind(self, P): # 测试使用 for i in P: print(i.solution) if __name__ == '__main__': solver = NSGAII() solver.solve() 参考文献[1] Coello C A C, Lechuga M S. MOPSO: A proposal for multiple objective particle swarm optimization[C]//Proceedings of the 2002 Congress on Evolutionary Computation. CEC'02 (Cat. No. 02TH8600). IEEE, 2002, 2: 1051-1056. [2] Deb K, Pratap A, Agarwal S, et al. A fast and elitist multiobjective genetic algorithm: NSGA-II[J]. IEEE transactions on evolutionary computation, 2002, 6(2): 182-197.
-
启发式优化算法学习-模拟退火 模拟退火算法(SA)参考教程 https://blog.csdn.net/brilliantZC/article/details/124436967模拟退火算法(Simulated Annealing,SA)是一种模拟物理退火过程而设计的优化算法。模拟退火算法采用类似于物理退火的过程。先在一个高温状态下(算法初始化随机解),然后逐渐退火,在每个温度下慢慢冷却,最终达到物理基态(相当于算法找到最优解)。模拟退火算法采用Metropolis准则,并用一组称为冷却进度表的参数控制算法的进程,使得算法在多项式时间里可以给出一个近似最优解。SA算法运行流程step1: 设定当前解(即为当前的最优解):令$ T =T_0 $,即开始退火的初始温度,随机生成一个初始解$ x_0 $,并计算相应的目标函数值$ E(x_0) $。step2: 产生新解与当前解差值:根据当前解$ x_i $进行扰动,产生一个新解$ x_j $,计算相应的目标函数值$ E(x_j)$,得到$ \Delta E = E(x_j)-E(x_i)$。step3: 判断新解是否被接受 :若$ \Delta E \leq 0 $,则新解$ x_j $被接受;若$ \Delta E> 0 $,则新解$ x_j $按概率$ e^{\frac{-(E(x_j)-E(x_i))}{T_i}} $被接受,$ T_i $为当前温度。step4: 当新解被确定接受时,新解$ x_j $被作为当前解。step5: 循环以上四个步骤:在温度$ T_i $下,重复$ k $次的扰动和接受过程,接着执行下一步骤。step6: 最后找到全局最优解:判断$ T $是否已经达到终止温度$ T_f $,是,则终止算法;否,则转到循环步骤继续执行。SA算法求解映射问题映射问题本质上可以看作一个序列的排序问题,使用SA算法求解时,需要关注的是如何产生新解,这里我们采用如下的方法:再序列中随机选取两个不重合的位置,将这两个位置中间的序列反转达到局部扰动的目的。SA算法求解映射问题代码# -*- coding: utf-8 -*- # Lishengxie # 2023-02-23 # Implementation of a Simulated Annealing algorithm for crossbar mapping/placing # 参考链接: https://blog.csdn.net/weixin_58427214/article/details/125901431 # 参考链接: https://blog.csdn.net/brilliantZC/article/details/124436967 import numpy as np import copy import sys import random class SAPlacer: """ SA algorithm ------------- Class used to find the mapping from computing cores to routers on NoC which minizes the communication cost """ def __init__(self, dim_x, dim_y, spike_table, L=200, K=0.95, S=0.04, T=100, T_threshold=0.01): """ Initialization of PsoPlacer. Args: dim_x: int, the `x` dimension on NoC dim_y: int, the `y` dimension on NoC spike_table: 2D-array, the number of spikes between core `i` and core `j` L: int, 每个温度下的迭代次数 K: float, 温度的衰减参数, T = K*T S: float, 步长因子 T: float, 初始温度 T_threshold: float, 终止温度 """ self.dim_x = dim_x self.dim_y = dim_y self.dim_size = dim_x * dim_y self.L = L self.K = K self.S = S self.T = T self.T_threshold = T_threshold if spike_table is not None: self.init_solution(spike_table) def init_solution(self, spike_table): """ Init spike table, hop distance table and solution. """ # init spike table self.spike_table = np.zeros((self.dim_size, self.dim_size)) h, w = spike_table.shape for i in range(h): for j in range(w): self.spike_table[i,j] = spike_table[i,j] # init hop distance table self.hop_xy() # init solution self.pre_x = np.arange(self.dim_size) np.random.shuffle(self.pre_x) self.pre_bestx = self.pre_x self.pre_x = np.arange(self.dim_size) np.random.shuffle(self.pre_x) self.prex_cost = self.fitnessFuntcion(self.pre_x) self.bestx = self.pre_x self.bestx_cost = self.fitnessFuntcion(self.bestx) def hop_xy(self): """ The hop distance between router `x` and `y` in the 2D-Mesh NoC using XY routing """ self.hop_dist = np.zeros((self.dim_size, self.dim_size)) for i in range(self.dim_size): for j in range(self.dim_size): self.hop_dist[i,j] = abs(i % self.dim_x - j % self.dim_x) \ + abs(i // self.dim_x - j // self.dim_x) def fitnessFuntcion(self, solution): """ Compute the communication cost for each mapping solution Args: solution: List, a possible mapping solution """ cost = 0 for i in range(self.dim_size): for j in range(self.dim_size): cost += self.spike_table[i,j] * self.hop_dist[solution[i], solution[j]] return cost def place(self): """ Execute the Simulated Annealing algorithm """ P = 0 next_x = np.arange(self.dim_size) np.random.shuffle(next_x) nextx_cost = self.fitnessFuntcion(next_x) while (self.T > self.T_threshold): self.T = self.K * self.T # 降温 # 当前温度T下迭代次数 for i in range(self.L): # ====在此点附近随机选下一点===== # 选择两个随机位置, 将两个位置之间的数组进行翻转 positions = np.random.choice(list(range(self.dim_size)), replace=False, size=2) x = min(positions[0], positions[1]) y = max(positions[0], positions[1]) mid_reversed = next_x[x:y+1][::-1] next_x[x:y+1] = mid_reversed if random.random() <= 0.0001: np.random.shuffle(next_x) nextx_cost = self.fitnessFuntcion(next_x) if nextx_cost < self.bestx_cost: self.pre_bestx = self.bestx self.bestx = next_x self.bestx_cost = nextx_cost if nextx_cost < self.prex_cost: self.pre_x = next_x self.prex_cost = nextx_cost P = P + 1 else: changer = -1 * (nextx_cost - self.prex_cost) / self.T p1 = np.exp(changer) if p1 > np.random.random(): self.pre_x = next_x self.prex_cost = nextx_cost P = P + 1 print("Current T: {:.7f}, best cost: {}".format(self.T, self.bestx_cost)) return self.bestx
-
启发式优化算法学习-PSO 粒子群算法(PSO)参考教程:https://cloud.tencent.com/developer/article/1424756粒子群算法是一种利用群体智能建立的一个简化模型,基于群体中个体对信息的共享使整个群体的运动趋向最优解。粒子群算法使用一群粒子,粒子拥有位置和速度两种属性,根据自身已经找到的最优解和参考整个共享于整个集群中找到的最优解去改变自己的飞行速度和位置。粒子速度和位置粒子群算法使用一定数量的粒子,粒子$ i $在$ N $维空间中的位置和速度表示为$ x_i=(x_1,x_2,\cdots,x_N) $ 和 $ v_i=(v_1,v_2,\cdots,v_N) $。每个粒子都有一个目标函数决定的适应值(fitness value),并且知道自己到目前为止发现的最好位置(pbest)和现在的位置$ x_i $。这个可以看作是粒子自己的飞行经验。除此之外,每个粒子还知道到目前为止整个群体中所有粒子发现的最好位置(gbest)(gbest是pbest中的最好值),这个可以看作是粒子同伴的经验。粒子就是通过自己的经验和同伴中最好的经验来决定下一步的运动。粒子速度和位置更新公式粒子群算法会给每个粒子一个初始的随机解,并通过迭代寻找最优解,迭代规则如下图所示:迭代公式中的第一部分和第二部分分别反映了粒子对自身经验和群体经验的学习。基于上述公式还可以对当前的速度引入更新权重PSO算法运行流程1)初始化一群微粒(群体规模为N),包括随机位置和速度;2)评价每个微粒的适应度;3)对每个微粒,将其适应值与其经过的最好位置pbest作比较,如果较好,则将其作为当前的最好位置pbest;4)对每个微粒,将其适应值与其经过的最好位置gbest作比较,如果较好,则将其作为当前的最好位置gbest;5)根据公式(2)、(3)调整微粒速度和位置;6)未达到结束条件则转第2)步。 迭代终止条件根据具体问题一般选为最大迭代次数Gk或(和)微粒群迄今为止搜索到的最优位置满足预定最小适应阈值。PSO算法求解映射问题映射问题本质上可以看作一个序列的排序问题,使用PSO算法求解映射问题时,粒子位置对应一个序列的排序。这里$ pbest-x_i^{t-1} $对应将$ x_i^{t-1} $转换成pbest所需要的交换序列,这里的迭代公式的含义变为对于原来的解序列$ x_i^{t-1} $,先按照$ c_2 $的概率使用$ pbest-x_i^{t-1} $的交换序列对$ x_i^{t-1} $进行交换获得$ (x_i^{t-1})^{'} $,再按照$ c_3 $的概率使用$ gbest-(x_i^{t-1})^{'} $的交换序列对$ (x_i^{t-1})^{'} $进行交换获得$ x_i^{t} $.PSO求解映射代码# -*- coding: utf-8 -*- # Lishengxie # 2023-02-19 # Implementation of a PSO algorithm for crossbar mapping/placing import numpy as np import copy import sys class PsoPlacer: """ PSO algorithm ------------- Class used to find the mapping from computing cores to routers on NoC which minizes the communication cost """ def __init__(self, dim_x, dim_y, spike_table, num_particle=50, s1=1.0, s2=0.04, s3=0.02): """ Initialization of PsoPlacer. Args: dim_x: int, the `x` dimension on NoC dim_y: int, the `y` dimension on NoC spike_table: 2D-array, the number of spikes between core `i` and core `j` num_particle: int, number of particles in the PSO algorithm """ self.dim_x = dim_x self.dim_y = dim_y self.dim_size = dim_x * dim_y self.num_particle = num_particle self.s1 = s1 self.s2 = s2 self.s3 = s3 self.init_particle(spike_table) def init_particle(self, spike_table): """ Init spike table, particles, local and global best solution Args: spike_table: 2D-array, the number of spikes between core `i` and core `j` """ # init the spike table, adding `0`s if the dimension of `spike_table` not equal to `dim_size` self.spike_table = np.zeros((self.dim_size, self.dim_size)) h, w = spike_table.shape for i in range(h): for j in range(w): self.spike_table[i,j] = spike_table[i,j] # init particle vectors with number of `num_particle`, each vector is a mappinng solution self.solution = np.zeros((self.num_particle, self.dim_size), dtype=np.int32) for i in range(self.num_particle): self.solution[i] = np.arange(self.dim_size) np.random.shuffle(self.solution[i]) # init hop distance table self.hop_xy() # init the local/global best solution and their cost self.local_best_solution = copy.deepcopy(self.solution) self.local_best_cost = np.zeros((self.num_particle,)) self.global_best_solution = np.arange(self.dim_size) self.global_best_cost = sys.maxsize for i in range(self.num_particle): self.local_best_cost[i] = self.fitnessFuntcion(self.local_best_solution[i]) if self.local_best_cost[i] < self.global_best_cost: self.global_best_solution = self.local_best_solution[i] self.global_best_cost = self.local_best_cost[i] print("Init, gloabal best cost:{}".format(self.global_best_cost)) def hop_xy(self): """ The hop distance between router `x` and `y` in the 2D-Mesh NoC using XY routing """ self.hop_dist = np.zeros((self.dim_size, self.dim_size)) for i in range(self.dim_size): for j in range(self.dim_size): self.hop_dist[i,j] = abs(i % self.dim_x - j % self.dim_x) \ + abs(i // self.dim_x - j // self.dim_x) def fitnessFuntcion(self, solution): """ Compute the communication cost for each mapping solution Args: solution: List, a possible mapping solution """ cost = 0 for i in range(self.dim_size): for j in range(self.dim_size): cost += self.spike_table[i,j] * self.hop_dist[solution[i], solution[j]] return cost def compute_swap_sequence(self, src_seq, dst_seq, seq_len): # TODO: Optimize this algorithm. """ Find the swap sequence from source sequecne to destination sequence. Args: src_seq: List, the source sequence dst_seq: List, the destination sequence seq_len: int, the length of source and destination sequence Return: swap_sequence: the index of each point for `src_seq` in `dst_seq` """ swap_seq = np.zeros((seq_len,)) for i in range(seq_len): swap_seq[i] = np.where(dst_seq == src_seq[i])[0] return swap_seq def applySwap(self, swap_seq, src_seq, seq_len): """ Apply swap sequence to the source sequence Args: src_seq: List, the source sequence swap_sequence: the index of each point for `src_seq` in `dst_seq` seq_len: int, the length of source and destination sequence Return: dst_seq: List, the destination sequence """ dst_seq = np.zeros((seq_len,)) for i in range(seq_len): dst_seq[swap_seq[i]] = src_seq[i] return dst_seq def place(self, num_iter=10): """ Funciton to execute pso algorithm. Args: num_iter: int, max number of iterations to execute pso update Return: global best solution after `num_iter` iterations """ for iter in range(num_iter): for i in range(self.num_particle): tmp_solution = copy.deepcopy(self.solution[i]) if np.random.random() <= self.s2: # print("local") swap_seq_local = self.compute_swap_sequence(tmp_solution, self.local_best_solution[i], self.dim_size) self.solution[i] = self.applySwap(self.solution[i], swap_seq_local, self.dim_size) if np.random.random() <= self.s3: # print("global") swap_seq_global = self.compute_swap_sequence(tmp_solution, self.global_best_solution, self.dim_size) self.solution[i] = self.applySwap(self.solution[i], swap_seq_global, self.dim_size) if np.random.random() <= 0.0001: np.random.shuffle(self.solution[i]) cost = self.fitnessFuntcion(self.solution[i]) if cost < self.local_best_cost[i]: self.local_best_cost[i] = cost self.local_best_solution[i] = copy.deepcopy(self.solution[i]) if self.local_best_cost[i] < self.global_best_cost: self.global_best_cost = self.local_best_cost[i] self.global_best_solution = copy.deepcopy(self.local_best_solution[i]) print("Iteration:{}, global best cost:{}".format(iter, self.global_best_cost)) return self.global_best_solution