标签搜索


搜索到
32
篇与
的结果
-
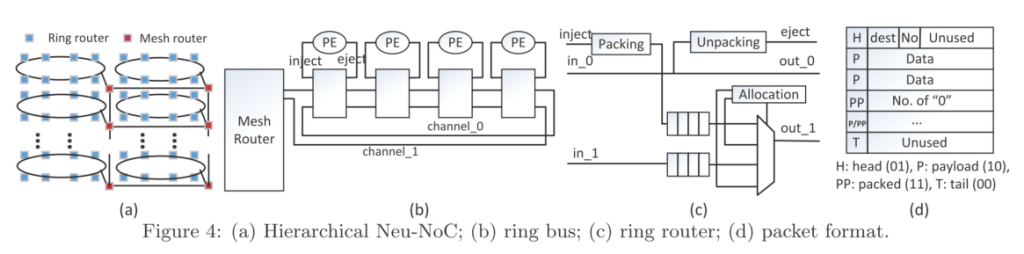
 SNN映射论文阅读-Neu-NoC Neu-NoC: A High-efficient Interconnection Network for Accelerated Neuromorphic Systems提出了一种环形+Mesh结合的NoC结构,同时基于该结构提出了相应的映射算法、广播协议和基于权重稀疏性的通信量减少方案,相较于现有的2D-Mesh的方法有效地减少了通信的延迟和能量消耗。 Motivation 相邻层之间通信频繁,导致NoC中大部分的通信量分布在较少的通信信道上; 全连接层中前一层的一个神经元给下一层的所有神经元发送的数据本质上是一样的,因此传输的数据包中有相当一部分是重复的数据。 Neu-NoC结构介绍 Mesh+ring结合,同一层中的神经元映射到一个ring中来减少数据的搬运,ring中提供两条信道,分别用于接收和发送数据以提高信息的传输速度; ring中使用ring路由,根据上图c)可以看到ring路由包含相应的2选1多选器、缓存和打包解包模块,同时提供分配模块用于仲裁(例如,正在传输的包比刚输入的包优先级更高) NN-aware Mapping 将神经元映射到具体的物理计算核心上,使得神经元之间的通信跳数最小 本质是贪婪算法,寻找局部最优的映射方案 packet广播在packet的header中添加一段标志位用于支持广播协议,标志位长度和Mesh路由的总数目相同;如1->7->9->10中分别广播到9和10,因此将9和10的标志位置为1,经过9后,9的标志位被置为0随后继续传递给10;稀疏感知的通信量减少 利用神经网络中特征图的稀疏性,提出了all-zero flit,该flit中使用特殊标志位,同时在payload中指出有多少个连续的全0包。根据这种方式将多个全0的数据包压缩成一个,由Mesh和ring之间的路由提供支持。 实验 针对全连接层 基于Booksim仿真器:https://github.com/booksim/booksim2 ring中的局部延迟和全局通信跳数随着同一个ring中支持的PE数量增加呈现出先增后减的趋势; 实验中发现通过将低于某个阈值的激活值置为0,提高特征图的稀疏性之后,精度不会受到严重的影响,因此可以在提高稀疏性和保持精度之间做一定的权衡; 提出的方法可以获得较好的性能,相较于普通的2D-Mesh的方法可以降低23.2%的包传输延迟和31.1%的能量消耗。 思考: ring加Mesh结合的方法比较有特点; 能否直接在现有的2D-Mesh之间实现相应的映射方法,将同一层的神经元映射到相邻的PE上,但是相较于顺序方式需要一定的性能提升? 多播和0数据压缩的方式可以参考,尤其是对于SNN可以在时间维度上进行压缩,减少传输的延迟。
SNN映射论文阅读-Neu-NoC Neu-NoC: A High-efficient Interconnection Network for Accelerated Neuromorphic Systems提出了一种环形+Mesh结合的NoC结构,同时基于该结构提出了相应的映射算法、广播协议和基于权重稀疏性的通信量减少方案,相较于现有的2D-Mesh的方法有效地减少了通信的延迟和能量消耗。 Motivation 相邻层之间通信频繁,导致NoC中大部分的通信量分布在较少的通信信道上; 全连接层中前一层的一个神经元给下一层的所有神经元发送的数据本质上是一样的,因此传输的数据包中有相当一部分是重复的数据。 Neu-NoC结构介绍 Mesh+ring结合,同一层中的神经元映射到一个ring中来减少数据的搬运,ring中提供两条信道,分别用于接收和发送数据以提高信息的传输速度; ring中使用ring路由,根据上图c)可以看到ring路由包含相应的2选1多选器、缓存和打包解包模块,同时提供分配模块用于仲裁(例如,正在传输的包比刚输入的包优先级更高) NN-aware Mapping 将神经元映射到具体的物理计算核心上,使得神经元之间的通信跳数最小 本质是贪婪算法,寻找局部最优的映射方案 packet广播在packet的header中添加一段标志位用于支持广播协议,标志位长度和Mesh路由的总数目相同;如1->7->9->10中分别广播到9和10,因此将9和10的标志位置为1,经过9后,9的标志位被置为0随后继续传递给10;稀疏感知的通信量减少 利用神经网络中特征图的稀疏性,提出了all-zero flit,该flit中使用特殊标志位,同时在payload中指出有多少个连续的全0包。根据这种方式将多个全0的数据包压缩成一个,由Mesh和ring之间的路由提供支持。 实验 针对全连接层 基于Booksim仿真器:https://github.com/booksim/booksim2 ring中的局部延迟和全局通信跳数随着同一个ring中支持的PE数量增加呈现出先增后减的趋势; 实验中发现通过将低于某个阈值的激活值置为0,提高特征图的稀疏性之后,精度不会受到严重的影响,因此可以在提高稀疏性和保持精度之间做一定的权衡; 提出的方法可以获得较好的性能,相较于普通的2D-Mesh的方法可以降低23.2%的包传输延迟和31.1%的能量消耗。 思考: ring加Mesh结合的方法比较有特点; 能否直接在现有的2D-Mesh之间实现相应的映射方法,将同一层的神经元映射到相邻的PE上,但是相较于顺序方式需要一定的性能提升? 多播和0数据压缩的方式可以参考,尤其是对于SNN可以在时间维度上进行压缩,减少传输的延迟。 -
SystemC学习 视频教程教程链接创建模块#include <systemc.h> // SC_MODULE声明模块,and2对应模块名 SC_MODULE(and2){ // sc_in声明输入端口,DT对应端口变量数据类型 sc_in<DT> a; sc_in<DT> b; // 声明时钟信号 sc_in<bool> clk; // sc_out声明输出端口 sc_out<DT> f; void func() { // 输入端口读数据.read() // 输出端口写数据.write() f.write(a.read() & b.read()); } // 模块构造函数 SC_CTOR(and2){ // 声明线程 SC_METHOD(func); // 线程声明后紧接着声明敏感信号列表,以 << 号隔开 // 声明a和b为敏感信号 sensitive << a << b; // 声明clk的上升沿为敏感信号,下降沿为.neg() // sensitive << clk.pos(); } } Threads A function made to act like a hardware process Run concurrently; Sensitive to signals, clock edges or fixed amounts of simulation time; Not called by the user, always active 支持三种threads SC_METHOD() Executes once every sensitive event Run continuously 类似于Verilog @always block 可综合 组合逻辑或者简单时序逻辑 SC_THREAD() 只在simulation开始时运行一次 可以使用无限循环来以固定频率执行代码段 类似于Verilog @initial block 不可综合 在testbench中用于初始化、描述时钟等 SC_CTHREAD() "clocked thread" Run continuously References a clock edge 可综合 Can take one or more clock cycles to execute a single iteration Datatypes SystemC has bit-accurate Integer Datatypes Unsigned and signed sc_uint<N> N是位宽 sc_int<N> SC_CTHREAD Clocked Threads SC_METHOD限制 Limited to one cycle Fine for counters or simple sequential designs Not much different than hand coded RTL Can't handle multi-cycle algorithms SC_CTHREAD Not limited to one cycle Can contain continuous loops Can contain large blocks of code with operations or control Great for behavioral synthesis SC_CTHREAD是SC_CTHREAD的一种特殊情况,SC_CTHREAD能产生更好的综合效果。SC_CTHREAD中可以使用wait()函数。 SC_CTHREAD中第二个参数需要传入时钟参数,(clk,pos()/clk.neg()) SC_CTHREAD(fir_main, clk.pos()); reset_signal_is(rst, true); Testbench Top level structural module sc_main() funciton定义程序主函数 sc_signal<> 用于定义信号线连接模块之间的端口 sc_clock 定义clock信号 sc_clk clk_sig; // 构造函数中传入时钟信号,这里SC_NS指ns,10表示10ns为一个时钟周期 SC_CTOR(SYSTEM):clk_sig("clk_sig", 10, SC_NS) sc_start()、sc_stop()开始和终止仿真 Handshaking valid/ready信号组 Latency// 记录时间 sc_time start_time, end_time, clk_period; start_time = sc_time_stamp(); // 获取时钟周期, clk是之前声明的时钟信号 sc_clock *clk_p = DCAST<sc_clock*>(clk.get_interface()); clock_period = clk_p -> period(); C++ Segmentation Faulthttps://zhuanlan.zhihu.com/p/397148839
-
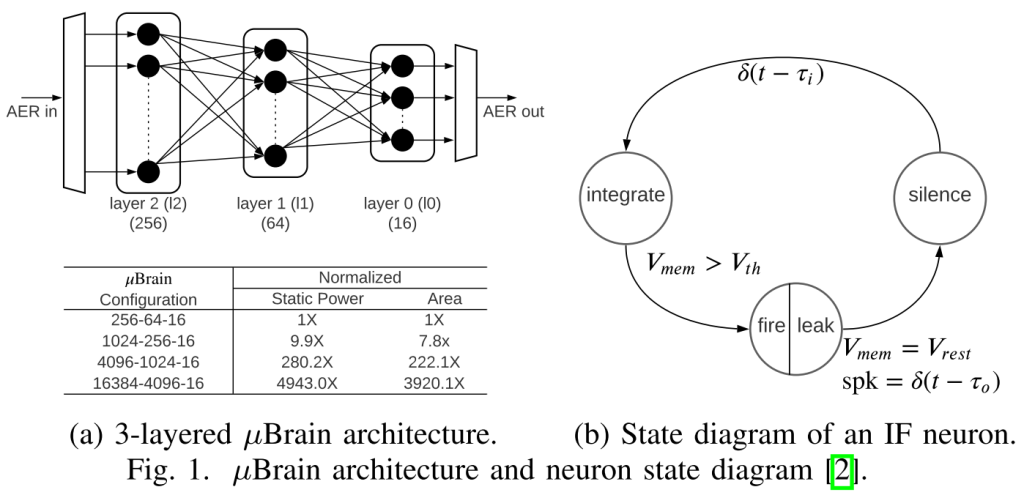
SNN映射论文阅读-SentryOS SentryOS: Design of Many-Core Big Little µBrains for Energy-Efficient Embedded Neuromorphic Computing 开源地址: 暂无 使用芯片: µBrain 优化指标: 芯片使用面积和功耗在uBrain神经形态核心上拓展实现的神经形态系统(基于分段总线)和映射框架(SentryOS)。 - 使用分段总线,实现核心之间的一对一互联(实际根据运行数据存在分时复用); - 基于异构大小核,大网络分割后的子网络规模不同,使用异构大小核来减少uBrain核心中的硬件空闲率uBrain使用的三层全连接结构 异构大小核设计 根据uBrain中使用的三层全连接结构,作者分析了LeNet、AlextNet、VGGNet、ResNet和DenseNet五种模型中L1和L2 neighbors 的数目,发现对于不同应用差别较大,因此使用异构的不同大小的uBrain核心可以提高硬件资源(神经元和突触连接)的利用率。 分段总线互联 文中使用分段总线连接不同的uBrain核心来完成通信,相较于传统的共享式的总线结构,分段式总线结构可以价格总线分段,不同段之间可以并行通信,互不影响。为了实现同一时刻所有核心之间可以并行通信,需要多条并行总线,基于训练数据获取到同一时刻最大的并行通行量,从而可以确定所需要的最小的并行总线数目。 SentryOS设计 a. SentryC编译器 将大网络分割成多个可以映射到uBrain核心的子网络,具体的映射算法如下,主要分为四个步骤 i. 对于每个输出神经元,根据神经元到其的最长路径计算两者之间的距离; ii. 根据第一步算出的距离给神经元添加索引,需要确保所有子网络中的神经元具有连续索引(论文中的阐述) iii. 将所有距离小于2的神经元形成集合,$ S_0 = {N_j | dist(N_j ) ≤ 2} $,产生一个子网络,剩下的神经元递归组成其他子网络,这一步中可能会插入权重为1的神经元(调整阈值每来一个脉冲就发放一个脉冲?); iv. 融合两个子网络$ S_i $ 和$ S_j $ 当且仅当 $$Area(S_i,j) \lt Area(S_i) + Area(S_j)$$ $$Power(S_i,j)\lt Power(S_i)+ Power(S_j)$$ 文中提到可以将SentryOS的方案扩展到基于crossbar的神经形态硬件上,即认为crossbar为两层全连接结构(uBrain是三层) b. SentryRT运行时 类似于DFSynthesizer,使用Max-Plus Algebras的方式确定自网络之间的执行顺序,这篇文章在DFSynthesizer上进一步改善,一方面使用多流水线来执行一个网络,另一方面使用Batch依次运算多个输入图片提高吞吐量。 实验评估 a. 使用异构大小核设计可以提高突触等资源的利用率,降低能量消耗,提高吞吐量; b. 使用分段总线可以避免运行整段总线,同时基于训练数据最小化了总线数目,降低了能量消耗;另一方面,uBrain核心之间通信不再需要路由算法,在映射时所有的通信方案已经确定,减少了通信的延迟。
-
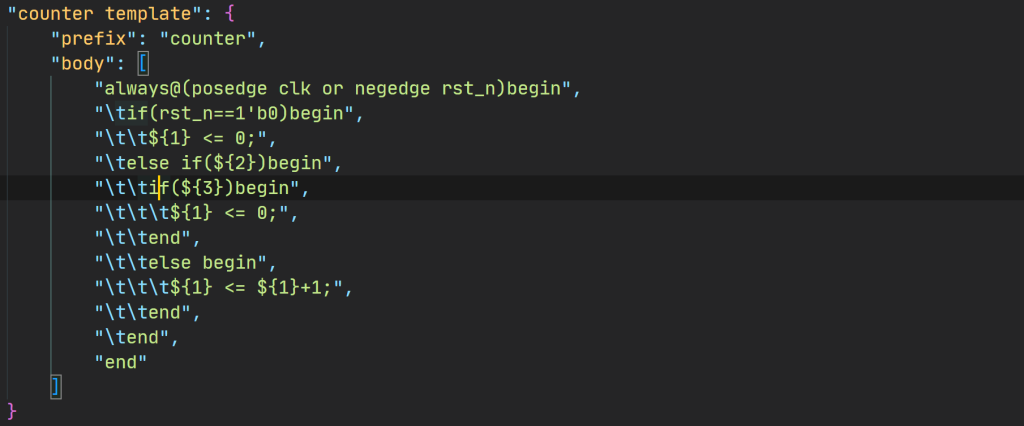
verilog学习笔记 参考书籍:《手把手教你学FPGA设计:基于大道至简的至简设计法》百度网盘链接:https://pan.baidu.com/s/12knuxzb4Z6z_8gR-By-l-A 提取码:mwzd自己实现的书中的模块和相应的testbench测试:https://github.com/lishengxie/verilog-learning.git计数器设计规则 计数器需要考虑三要素:初值、加一条件和结束值(通常依次考虑); 计数初值必须为0; 使用某个计数值时必须同时满足加1条件;例如加1条件为add_cnt且add_cnt && cnt==4时表示计数到第五个,而add_cnt==0 && cnt==4不表示计数到第五个; 计数条件必须同时满足加一条件,且结束值必须是x-1的形式; 当从计数器取某个数时,assign形式必须为:(加一条件) && (cnt==计数值-1); 结束后计数值需要回到0; 需要限定范围时,推荐使用>=和<两种符号,尽量不要使用大于或者小于等于两种符号; 计数器设计时,先写计数器的always段,条件用名字代替,随后使用assign语句依次写出加一条件和结束条件;由此可以得出计数器的模板写法如下所示 // 中文词语方便理解,实际使用需要更改为相应的变量名 always @(posedge clk or negedge rst_n) begin if(rst_n==1'b0)begin cnt <= 0; end else if(加一条件)begin if(结束条件) cnt <= 0; else cnt <= cnt + 1; end end assign 加一条件 = xxxxxx; assign 结束条件 = (加一条件) && (cnt==计数值-1); 加一条件必须与计数器严格对齐,其他信号一律向计数器对齐;例如,现在需要输出两个信号dout0和dout1,dout0在计数到6时拉高,dout1在计数到7时拉高,因此dout0变1的条件为add_cnt && cnt==6-1,dout1变1的条件有两种写法 dout0 == 1 add_cnt && cnt==7-1 第一种写法是间接向计数器对齐,是非常不好的方法,建议使用第二种直接向计数器对齐; 加一条件统一前缀为add_,结束条件统一前缀为end_; 暂不使用减1计数器。 状态机设计规则 使用四段式写法 第一段为同步时序的always模块,用于格式化描述次态迁移到现态寄存器; always @(posedge clk or negedge rst_n) begin if(!rst_n) begin state_c <= IDLE; end else begin state_c <= state_n; end end 第二段为组合逻辑的always块,用于描述状态转移条件判断,以三个状态的状态机IDLE->S1->S2->IDLE为例;always @(*) begin case(state_c) IDLE: begin if(idle2s1_start) begin state_n = S1; end else begin state_n = state_c; end end S1: begin if(s12s2_start) begin state_n = S2; end else begin state_n = state_c; end end S2: begin if(s22_idle_start) begin state_n = S2; end else begin state_n = state_c; end end default: begin state_n = IDLE; end endcase end 第三段定义转移条件,注意条件一定要加上现态。assign idle2s1_start = state_c == IDLE && xxxx; assign s12s2_start = state_c == S1 && xxxx; assign s22idle_start = state_c == S2 && xxxx; 第四段设计输出信号,每一个输出信号使用一个always块always @(posedge clk or negedge rst_n) begin if(!rst_n) begin out1 <= 1'b0 end else if(state_c==S1)begin out <= 1'b1; end else begin out <= 1'b0; end end 四段式状态机第一段写法可以保持不变; 第二段中的状态转移条件用信号名表示,无需写出具体的转移条件; 用assign形式将状态转移条件写成xx2xx_start的形式; 状态转移条件,用assign产生变化条件时必须加上当前状态; 状态保持不变使用state_n = state_c,因为如果在组合逻辑中使用state_n = state_n,只有锁存器才能有保持电路,而锁存器在数字电路中通常是不希望出现的。 FIFO设计规则 使用Show-ahead模式。FIFO有两种使用模式,分别是Normal和Show-ahead模式,其中Normal模式指先有读使能,之后FIFO才输出这个数据;而Show-ahead模式指FIFO先输出数据,遇到读使能后FIFO更新输出数据。两种模式只有读数据时存在区别,使用Show-ahead模式的好处在于读请求信号读数据同时有效,可以当做有效数据使用 读、写隔离,读控制和写控制是相互独立的,相互之间除了用FIFO交流信息外,不能有任何信息传递。 读使能必须判断空状态,并且用组合逻辑产生。原因在于使用Show-ahead模式当FIFO为空时,如果使用时序逻辑产生读使能,会出现在FIFO为空的情况下读数据的操作,读操作会出错。 处理报文时将指示信号和数据一起存入FIFO,这样做的好处是可以将报文数据、报文头、报文尾的指示信号和数据一起原封不动地送入下游模块。 读写时钟不同时,必须使用异步FIFO。 VScode verilog使用笔记编写&添加Verilog代码段 编写代码段 * 顶部菜单栏 文件(File) -> 首选项(Preference) -> 用户代码段(User Snippets) * 选择verilog.json打开,添加代码段模板,以编写的计数器模板为例,如下所示 2. 插入代码段 Ctrl+Shift+P进入命令输入,输入Insert Snippet命令选择对应的代码段插入。数字电路相关三态门电路/inout端口 - 当sio_out_en=0 时,此时sio_d作为输出口,sio_d输出sio_out的值; - 当sio_out_en=1 时,此时sio_d作为输入口,sio_din输出sio_d的输入值;inout_sio_d; assign sio_d = sio_out_en ? Sio_out : 1'bz; assign sio_din = sio_d;
-
go-gin-chat项目学习 项目地址:https://github.com/hezhizheng/go-gin-chatGin框架学习参考笔记Websocket学习Websocket连接是升级的HTTP连接,在连接被客户端或服务器终止之前一直存在,基于Websocket可以实现客户端和服务端之间的双工通信,而不需要对HTTP端口进行持续轮询,大大节省了网络资源开销。go-gin-chat中基于gorilla/websocket实现websocket的使用,下面是该软件包使用的示例,可以参考博客。// We'll need to define an Upgrader // this will require a Read and Write buffer size var upgrader = websocket.Upgrader{ ReadBufferSize: 1024, WriteBufferSize: 1024, } func wsEndpoint(w http.ResponseWriter, r *http.Request) { upgrader.CheckOrigin = func(r *http.Request) bool { return true } // upgrade this connection to a WebSocket connection ws, err := upgrader.Upgrade(w, r, nil) if err != nil { log.Println(err) } // 向连接的客户端写入信息 log.Println("Client Connected") err = ws.WriteMessage(1, []byte("Hi Client!")) if err != nil { log.Println(err) } // listen indefinitely for new messages coming // through on our WebSocket connection go reader(ws) } // define a reader which will listen for // new messages being sent to our WebSocket // endpoint func reader(conn *websocket.Conn) { for { // read in a message messageType, p, err := conn.ReadMessage() if err != nil { log.Println(err) return } // print out that message for clarity fmt.Println(string(p)) if err := conn.WriteMessage(messageType, p); err != nil { log.Println(err) return } } } Websocket心跳检测参考博客 https://www.cnblogs.com/tugenhua0707/p/8648044.html在使用websocket的过程中,如果网络断开而服务器没有触发onclose事件,那么服务器会继续向客户端发送数据,这些数据将被丢失。需要心跳机制来检测客户端和服务端之间是否处于正常的链接状态。心跳机制的大致实现方式为:每隔一段时间客户端向服务器发送一个数据包,通知服务器自己还活着,如果链接还存在服务器会发送一个数据包给客户端,客户端确认服务端也活着,否则的话可能是链接已经断开,需要重新链接。发送顺序也可以反过来由服务器向客户端发送ping信息,由客户端反馈pong信息。go-gin-chat中使用了https://github.com/zimv/websocket-heartbeat-js中提供的心跳检测方法,由服务段发送ping信息("heartbeat"),客户端接收到这个ping信息后返回一个pong信息,服务端重置心跳倒计时。postman使用进入postman网站注册用户并下载客户端,这里是使用postman进行POST请求提交json格式文件的示例。
-
Gin框架学习 概述Gin框架地址:https://github.com/gin-gonic/gin 参考文档: https://www.kancloud.cn/shuangdeyu/gin_book https://github.com/piexlmax/1010classGin服务入门package main import "github.com/gin-gonic/gin" func main() { r := gin.Default() r.GET("/ping", func(c *gin.Context) { c.JSON(200, gin.H{ "message": "pong", }) }) r.Run() // listen and serve on 0.0.0.0:8080 } Gin获取Get/Post参数获取Get参数func main() { router := gin.Default() // 匹配的url格式: /welcome?firstname=Jane&lastname=Doe router.GET("/welcome", func(c *gin.Context) { firstname := c.DefaultQuery("firstname", "Guest") // DefaultQuery可以在参数值不存在时使用传入的默认值 lastname := c.Query("lastname") // 是 c.Request.URL.Query().Get("lastname") 的简写 c.String(http.StatusOK, "Hello %s %s", firstname, lastname) }) router.Run(":8080") } 获取Post参数func main() { router := gin.Default() router.POST("/form_post", func(c *gin.Context) { message := c.PostForm("message") nick := c.DefaultPostForm("nick", "anonymous") // 此方法可以设置默认值 c.JSON(200, gin.H{ "status": "posted", "message": message, "nick": nick, }) }) router.Run(":8080") } Get和Post参数混合使用 router := gin.Default() router.POST("/post", func(c *gin.Context) { id := c.Query("id") page := c.DefaultQuery("page", "0") name := c.PostForm("name") message := c.PostForm("message") fmt.Printf("id: %s; page: %s; name: %s; message: %s", id, page, name, message) }) router.Run(":8080") } 请求示例:POST /post?id=1234&page=1 HTTP/1.1 Content-Type: application/x-www-form-urlencoded name=manu&message=this_is_great Bind绑定参数&参数验证为了将请求主体绑定到结构体中,需要使用模型绑定,Gin当前支持JSON、XML、YAML和标准表单值(foo=bar&boo=baz)的绑定。可以使用Must Bind和Should Bind两种绑定方式,推荐使用Should Bind方式 Methods: ShouldBind, ShouldBindJSON, ShouldBindXML, ShouldBindQuery, ShouldBindYAML, 后几种基于ShouldBind实现相应的行为,可以指定绑定的数据格式,发生错误时会将错误返回供后续处理。下面给出了绑定json格式的示例 // 绑定为json type Login struct { User string `form:"user" json:"user" xml:"user" binding:"required"` Password string `form:"password" json:"password" xml:"password" binding:"required"` } func main() { router := gin.Default() // Example for binding JSON ({"user": "manu", "password": "123"}) router.POST("/loginJSON", func(c *gin.Context) { var json Login if err := c.ShouldBindJSON(&json); err != nil { c.JSON(http.StatusBadRequest, gin.H{"error": err.Error()}) return } if json.User != "manu" || json.Password != "123" { c.JSON(http.StatusUnauthorized, gin.H{"status": "unauthorized"}) return } c.JSON(http.StatusOK, gin.H{"status": "you are logged in"}) }) router.Run(":8080") } 绑定form,uri,xml格式时可以在结构体后的的修饰符中使用相应的字段。 参数验证一个字段用binding:"required"修饰,在绑定时如果该字段的值为空,那么将返回一个错误。可以在binding后使用自定义的验证函数,可以参考文档中提供的自定义验证的示例,需要注意文档中使用的验证器版本是v8,实际使用时版本不一致需要做出更改,可以参考视频教程。 Gin文件上传和返回文件读取上传文件的文件名可以由用户自定义,所以可能包含非法字符串,为了安全起见,应该由服务端统一文件名规则 上传文件的示例代码如下所示:单文件上传func main() { router := gin.Default() // 给表单限制上传大小 (默认 32 MiB) // router.MaxMultipartMemory = 8 << 20 // 8 MiB router.POST("/upload", func(c *gin.Context) { // 单文件 file, _ := c.FormFile("file") log.Println(file.Filename) // 上传文件到指定的路径 c.SaveUploadedFile(file, "./saved.txt") c.String(http.StatusOK, fmt.Sprintf("'%s' uploaded!", file.Filename)) }) router.Run(":8080") } 使用FormFile接收单文件,使用Postman测试文件上传时,需要先设置Header中Content-Type为multipart/form-data,随后在Body中选择上传form-data类型的键值对,在具体的值中选择文件,同时需要注意Posterman上传文件时工作路径的设置。多文件上传主要区别在于先获取文件列表,再依次对每个文件进行处理。func main() { router := gin.Default() // 给表单限制上传大小 (默认 32 MiB) // router.MaxMultipartMemory = 8 << 20 // 8 MiB router.POST("/upload", func(c *gin.Context) { // 多文件 form, _ := c.MultipartForm() files := form.File["file"] for _, file := range files { log.Println(file.Filename) // 上传文件到指定的路径 // c.SaveUploadedFile(file, dst) } c.String(http.StatusOK, fmt.Sprintf("%d files uploaded!", len(files))) }) router.Run(":8080") } 文件返回// Header添加文件相关信息,不加也可以跑? c.Writer.Header().Add("Content-Disposition", fmt.Sprintf("attachment; filename=%s", file.Filename)) // 在服务器文件路径下启动相应的服务 c.File(dst) 路由分组和中间件路由分组对router创建Group就是分组,同一分组中会拥有同一前缀和同一中间件,分组可以使得路由结构更加清晰,更加方便管理路由。路由分组实例如下所示:func main() { router := gin.Default() // Simple group: v1 v1 := router.Group("/v1") { v1.POST("/login", loginEndpoint) v1.POST("/submit", submitEndpoint) v1.POST("/read", readEndpoint) } router.Run(":8080") } 中间件在请求到达路由的方法的前和后进行的一系列操作,在路由(路由组)上进行Use操作,后面传入中间件函数即可。// HandlerFunc defines the handler used by gin middleware as return value. type HandlerFunc func(*Context) HandlerFunc是一个函数类型,接收一个Context参数。用于编写程序处理函数并返回HandleFunc类型,作为中间件的定义。gin.Default()中默认已经使用了Recovery和Logger两个中间件,无中间件启动服务可以使用gin.New()方法。下面给出了Gin自定义中间件使用的实例func Logger() gin.HandlerFunc { return func(c *gin.Context) { t := time.Now() // Set example variable c.Set("example", "12345") // before request c.Next() // after request latency := time.Since(t) log.Print(latency) // access the status we are sending status := c.Writer.Status() log.Println(status) } } func main() { r := gin.New() r.Use(Logger()) r.GET("/test", func(c *gin.Context) { example := c.MustGet("example").(string) // it would print: "12345" log.Println(example) }) // Listen and serve on 0.0.0.0:8080 r.Run(":8080") } 中间件中context.Next函数可以将中间件代码的执行顺序一分为二,Next函数调用之前的代码在请求处理之前之前,当程序执行到context.Next时,会中断向下执行,转而先去执行具体的业务逻辑,执行完业务逻辑处理函数之后,程序会再次回到context.Next处,继续执行中间件中后续的代码。使用Use方法调用自定义的中间件,可以在路由或路由组后调用,需要注意的是,调用多个中间件时可以在一个Use方法中依次写入,也可以连续使用多个Use方法。多个中间件的代码执行顺序可以参考洋葱中间件模型。Gin日志可以参考文档相关章节。日志可以用来记录参数信息,猜测用户行为,尝试复现bug并修复,推荐使用第三方的日志工具go-logging,logrus等,对于大量的日志,可以使用go-file-rotatelogs, file-rotatelogs对日志自行按照时间进行切割等。记录用户的输入输出信息常使用中间件实现。Gin数据库使用链接和使用MySQL数据库import _ "github.com/go-sql-driver/mysql" connStr := "root:password@tcp(127.0.0.1:3306)/ginsql" db, err := sql.Open("mysql", connStr) if err != nil { log.Fatal(err.Error()) return } ORM进行数据库操作ORM是一种数据库辅助工具,可以在go结构体和数据库之间产生映射,基于结构体即可完成增删改查操作。可用的ORM框架有GORM,gorose和xorm等。GORM链接数据库GORM参考文档如下: https://learnku.com/docs/gorm/v2/index/9728 http://gorm.book.jasperxu.com/ (好像无法访问了) https://gorm.io/zh_CN/docs/connecting_to_the_database.html https://books.studygolang.com/gorm/ 1. 导入gorm 2. 导入mysql驱动器 3. 使用Open方法链接得到数据库对象,以MySQL为例dsn := "user:pass@tcp(127.0.0.1:3306)/dbname?charset=utf8mb4&parseTime=True&loc=Local" db, err := gorm.Open(mysql.Open(dsn), &gorm.Config{}) // 最后关闭数据库链接 defer db.Close() 加载静态资源&HTML渲染设置静态文件路径func main() { router := gin.Default() router.Static("/assets", "./assets") router.StaticFS("/more_static", http.Dir("my_file_system")) router.StaticFile("/favicon.ico", "./resources/favicon.ico") // Listen and serve on 0.0.0.0:8080 router.Run(":8080") } HTML渲染func main() { router := gin.Default() router.LoadHTMLGlob("templates/*") //router.LoadHTMLFiles("templates/template1.html", "templates/template2.html") router.GET("/index", func(c *gin.Context) { c.HTML(http.StatusOK, "index.tmpl", gin.H{ "title": "Main website", }) }) router.Run(":8080") } <html> <h1> {{ .title }} </h1> </html>
-
SNN映射论文阅读-NEUTRAMS Neutrams: NEUTRAMS: Neural Network Transformation and Co-design under Neuromorphic Hardware Constraints 开源代码地址:https://github.com/hoangt/neutrams 使用芯片:TianJi,Prime 优化指标:Crossbar之间的脉冲通信量图 1. NEUTRAMS提出的工具链的层级结构实现步骤: 1. 神经网络表示 类似其他模拟器中常用的方式,将神经网络看成神经元分组和神经元分组之间的连接组成。神经元分组之间都认为使用全连接,不存在的边认为使用权重为0的虚拟边。 2. Training-based transformation(神经网络训练&神经元分组) a. 使用BP算法训练神经网络 b. 连接稀疏化,通过交换矩阵的行或列来将连接矩阵转换为满足crossbar大小限制的多个子矩阵,并将其余连接权重置为0,目标是最大化剩余的原有连接的绝对值权重之和。 c. 权重量化,将原有的浮点数权重量化为低精度权重,同时使用BP算法微调模型(BP算法中仍然使用浮点数计算)。 d. 在原有的两层中间插入新的全连接层,对于大小为m和n的两个层之间的连接,插入$ \frac{m+n}{2} $的全连接层,重新训练后减少准确度的损失。 e. 对于复杂的神经网络(非顺序连接的/循环的):对于复杂的神经网络,可以通过图2所示的复制和合并的方式,逐层训练神经元分组之间的突触连接;对于循环神经网络,脉冲神经网络需要将循环连接暂时删除,然后记录循环连接中的信息,将上一时刻信息送入连接后神经元并保存当前时刻连接前神经元送入的信息。 图 2. 复杂神经网络训练3. Mapping 使用Kernighan-Lin(KL)算法进行神经元子块到crossbar上的映射,目标是最小化crossbar之间的脉冲通信量。 4. Cycle-accurate simulator实验 1. 考察指标:错误率,能量消耗,芯片有效速度(反比于每个仿真周期内的芯片时钟周期数,芯片有效速度的最大值对应于超过该值部分脉冲无法在一个仿真周期内到达目标神经元)。 2. 结论 a. 插入新的全连接层精度损失低于扩展crossbar规模,插入新的全连接层会增加能量损失、降低有效速度; b. 基于已训练的前神经元节点训练后节点可以避免误差的积累; c. 连接稀疏化对于精度影响较大,但是后续可以通过微调网络改善; d. 部分神经元参数可以同步变大或减小,而不影响最终的输出; e. 网络规模越大,芯片有效速度越小。
-
Linux常用命令记录 Vimvim删除文件中的所有内容: ESC确保退出编辑模式,按下":"切换到命令模式然后输入%d并执行 vim删除单行内容:将光标移动到需要删除的行,ESC确保退出编辑模式,按两次d键。 vim删除多行内容:将光标移动到需要删除的第一行,ESC确保退出编辑模式。在dd命令前面加上要删除的行数。例如,如果要删除第4行以下的3行,请先移动至第四行,再按下3dd。 vim撤销&恢复:u是撤销刚才做的动作,ctrl+r 是恢复刚才撤销的动作。文件操作参考博客https://www.cnblogs.com/liaojie970/p/6746230.html文件复制命令格式:cp [-adfilprsu] 源文件(source) 目标文件(destination) cp [option] source1 source2 source3 ... directory 参数说明:-a:是指archive的意思,也说是指复制所有的目录 -d:若源文件为连接文件(link file),则复制连接文件属性而非文件本身 -f:强制(force),若有重复或其它疑问时,不会询问用户,而强制复制 -i:若目标文件(destination)已存在,在覆盖时会先询问是否真的操作 -l:建立硬连接(hard link)的连接文件,而非复制文件本身 -p:与文件的属性一起复制,而非使用默认属性 -r:递归复制,用于目录的复制操作 -s:复制成符号连接文件(symbolic link),即“快捷方式”文件 -u:若目标文件比源文件旧,更新目标文件 如将/test1目录下的file1复制到/test3目录,并将文件名改为file2,可输入以下命令:cp /test1/file1 /test3/file2 文件移动命令格式:mv [-fiv] source destination 参数说明:-f:force,强制直接移动而不询问 -i:若目标文件(destination)已经存在,就会询问是否覆盖 -u:若目标文件已经存在,且源文件比较新,才会更新 如将/test1目录下的file1移动到/test3 目录,并将文件名改为file2,可输入以下命令:mv /test1/file1 /test3/file2 文件删除命令格式:rm [fir] 文件或目录 参数说明:-f:强制删除 -i:交互模式,在删除前询问用户是否操作 -r:递归删除,常用在目录的删除 如删除/test目录下的file1文件,可以输入以下命令:rm -i /test/file1 Windows 常用命令PowerShell创建新文件夹和新文件mkdir 文件夹名称 new-item 文件名称.文件格式 -type file
-
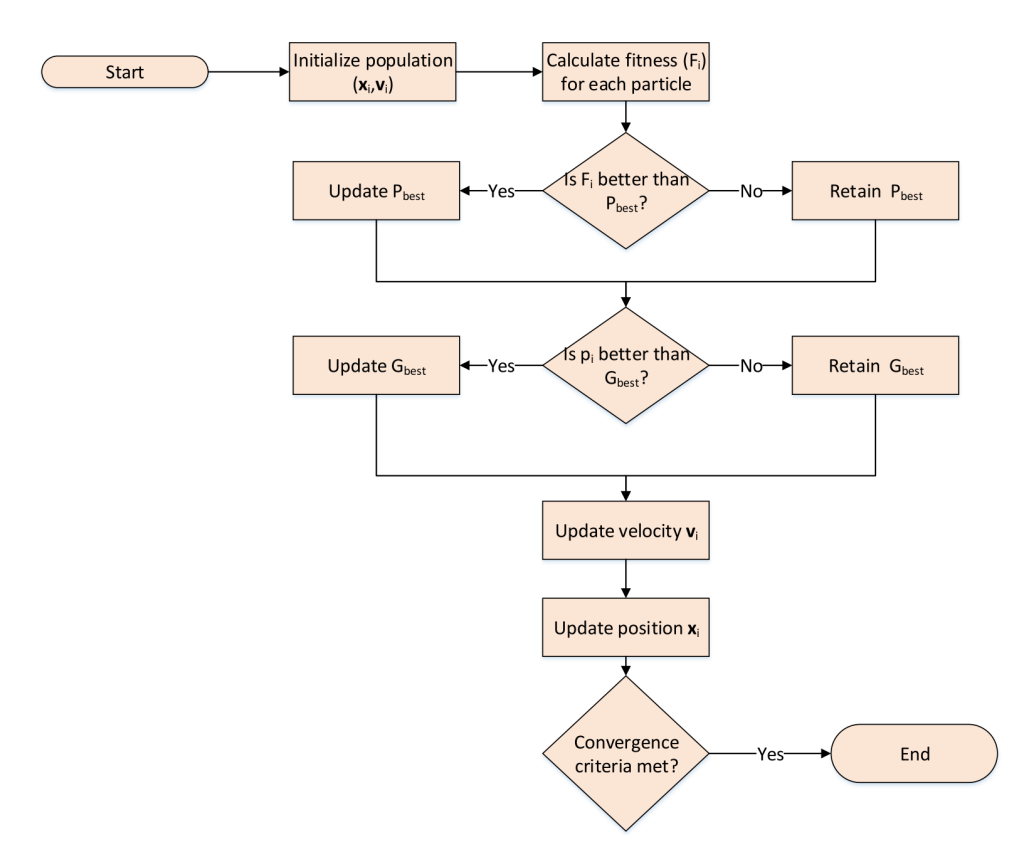
SNN映射论文阅读-PSOPART 图优化方法PSOPART Mapping of local and global synapses on spiking neuromorphic hardware 开源代码地址:https://github.com/Jinouwen/Mapping 优化指标:神经元分块之间的脉冲通信量 类脑芯片:CxQuad基本步骤 1. 使用Carlsim进行脉冲神经网络运行模拟,构建脉冲神经网络图结构; 2. 使用PSO(Partial Swarm Optimization)算法进行脉冲神经网络的分割,产生符合硬件限制的子块,这一步中优化的指标为神经元分块之间的脉冲通信量。图1. PSO算法执行流程创新点 提出使用进化算法(PSO)用于脉冲神经网络分割。问题 没有考虑到神经元分块到crossbar的物理映射问题,优化算法映射时间过长。
-
云服务器软件安装 Docker安装(Ubuntu 20.04):参考知乎博客 1. 更新软件包索引,并且安装必要的依赖软件sudo apt update sudo apt install apt-transport-https ca-certificates curl gnupg-agent software-properties-common 使用下面的 curl 导入源仓库的 GPG key: curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add - 将 Docker APT 软件源添加到你的系统: sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable" 安装Docker a. 安装最新版本的Docker sudo apt update sudo apt install docker-ce docker-ce-cli containerd.io b. 安装指定版本的docker # 列出所有可用的docker版本 sudo apt update apt list -a docker-ce # 安装docker sudo apt install docker-ce=<VERSION> docker-ce-cli=<VERSION> containerd.io docker-compose 安装 参考链接:https://blog.csdn.net/qq_35995514/article/details/125468792 验证安装成功 sudo systemctl status docker docker container run hello-world Golang安装:参考腾讯云博客 1. 下载程序包 浏览Go官方下载页面,下载程序包并解压到/usr/local目录下。 2. 添加环境变量 将Go目录添加到$PATH环境变量下,可以添加到/etc/profile或者$HOME/.profile下,export PATH=$PATH:/usr/local/go/bin # 后续Go环境使用 export GOPATH=/home/ubuntu/go export GOBIN=$GOPATH/bin export GOPROXY=https://goproxy.io,direct 前者代表系统范围内安装,后者为当前用户安装,保存文件并激活source /etc/profile 验证安装 验证Go版本 go version