标签搜索


搜索到
5
篇与
的结果
-
 LeetCode刷题-二叉树遍历迭代法 LeetCode题目链接二叉树的前序遍历:https://leetcode.cn/problems/binary-tree-preorder-traversal/ 二叉树的中序遍历:https://leetcode.cn/problems/binary-tree-inorder-traversal/ 二叉树的后序遍历:https://leetcode.cn/problems/binary-tree-postorder-traversal/二叉树的遍历方法有两种,分别是递归法和迭代法;实际使用中由于系统调用栈有限制,使用递归法可能会导致栈溢出,这里记录三种遍历的迭代做法。最后,介绍二叉树层序遍历的两种方法。迭代遍历法借助辅助栈实现,下面是二叉树节点的定义,使用链表实现。 struct TreeNode { int val; TreeNode *left; TreeNode *right; TreeNode() : val(0), left(nullptr), right(nullptr) {} TreeNode(int x) : val(x), left(nullptr), right(nullptr) {} TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {} }; 前序遍历前序遍历的顺序是中左右,每次先处理中间节点,那么先将根节点入栈,然后将右孩子入栈,再将左孩子入栈。先右后左的原因是因为入栈顺序和处理顺序是相反的。前序遍历的处理代码如下:class Solution { public: vector<int> preorderTraversal(TreeNode* root) { vector<int> res; stack<TreeNode*> st; if (root == NULL) { return res; } st.push(root); while (!st.empty()) { TreeNode *cur = st.top(); st.pop(); res.push_back(cur->val); if (cur->right) st.push(cur->right); if (cur->left) st.push(cur->left); } return res; } }; 中序遍历中序遍历处理顺序为左中右,先访问二叉树顶部的节点,随后逐层向下访问直到树最左侧的节点,再开始处理节点,这导致处理节点的顺序和访问节点的顺序不一致。中序遍历的迭代法如下所示:class Solution { public: vector<int> inorderTraversal(TreeNode* root) { vector<int> res; stack<TreeNode*> st; if (root == NULL) { return res; } TreeNode *cur = root; while (cur!=NULL || !st.empty()) { if (cur != NULL) { if (cur) st.push(cur); cur = cur->left; } else { cur = st.top(); st.pop(); res.push_back(cur->val); cur = cur->right; } } return res; } }; 后序遍历先序遍历是中左右,后续遍历是左右中,那么只需要调整一下先序遍历的代码顺序,就变成中右左的遍历顺序,然后在反转result数组,输出的结果顺序就是左右中了。后序遍历的代码如下所示:class Solution { public: vector<int> postorderTraversal(TreeNode* root) { vector<int> res; stack<TreeNode*> st; if (root == NULL) { return res; } st.push(root); while (!st.empty()) { TreeNode *cur = st.top(); st.pop(); if (cur->left) st.push(cur->left); if (cur->right) st.push(cur->right); res.push_back(cur->val); } reverse(res.begin(), res.end()); return res; } }; 统一的迭代遍历法参考https://programmercarl.com/%E4%BA%8C%E5%8F%89%E6%A0%91%E7%9A%84%E7%BB%9F%E4%B8%80%E8%BF%AD%E4%BB%A3%E6%B3%95.html 每次在待处理节点入栈后,加入一个NULL节点作为标记,之后在遇到NULL节点时处理栈中的下一个节点。需要注意的是,这种方法效率不高,节点可能会多次入栈。层序遍历// 迭代遍历,BFS基于队列 class Solution { public: vector<vector<int>> levelOrder(TreeNode* root) { vector<vector<int>> res; queue<TreeNode*> q; if (root == NULL) { return res; } q.push(root); while (!q.empty()) { int size =q.size(); vector<int> layer; for (int i = 0; i < size; ++i) { TreeNode *cur = q.front(); q.pop(); layer.push_back(cur->val); if (cur->left) q.push(cur->left); if (cur->right) q.push(cur->right); } res.push_back(layer); } return res; } }; // 递归,DFS class Solution { public: vector<vector<int>> levelOrder(TreeNode* root) { vector<vector<int>> res; queue<TreeNode*> q; if (root == NULL) { return res; } order(0, root, res); return res; } // DFS, 递归 void order(int depth, TreeNode *cur, vector<vector<int>> &res) { if (cur == NULL) return; if (res.size() == depth) res.push_back(vector<int>()); res[depth].push_back(cur->val); order(depth + 1, cur->left, res); order(depth + 1, cur->right, res); } };
LeetCode刷题-二叉树遍历迭代法 LeetCode题目链接二叉树的前序遍历:https://leetcode.cn/problems/binary-tree-preorder-traversal/ 二叉树的中序遍历:https://leetcode.cn/problems/binary-tree-inorder-traversal/ 二叉树的后序遍历:https://leetcode.cn/problems/binary-tree-postorder-traversal/二叉树的遍历方法有两种,分别是递归法和迭代法;实际使用中由于系统调用栈有限制,使用递归法可能会导致栈溢出,这里记录三种遍历的迭代做法。最后,介绍二叉树层序遍历的两种方法。迭代遍历法借助辅助栈实现,下面是二叉树节点的定义,使用链表实现。 struct TreeNode { int val; TreeNode *left; TreeNode *right; TreeNode() : val(0), left(nullptr), right(nullptr) {} TreeNode(int x) : val(x), left(nullptr), right(nullptr) {} TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {} }; 前序遍历前序遍历的顺序是中左右,每次先处理中间节点,那么先将根节点入栈,然后将右孩子入栈,再将左孩子入栈。先右后左的原因是因为入栈顺序和处理顺序是相反的。前序遍历的处理代码如下:class Solution { public: vector<int> preorderTraversal(TreeNode* root) { vector<int> res; stack<TreeNode*> st; if (root == NULL) { return res; } st.push(root); while (!st.empty()) { TreeNode *cur = st.top(); st.pop(); res.push_back(cur->val); if (cur->right) st.push(cur->right); if (cur->left) st.push(cur->left); } return res; } }; 中序遍历中序遍历处理顺序为左中右,先访问二叉树顶部的节点,随后逐层向下访问直到树最左侧的节点,再开始处理节点,这导致处理节点的顺序和访问节点的顺序不一致。中序遍历的迭代法如下所示:class Solution { public: vector<int> inorderTraversal(TreeNode* root) { vector<int> res; stack<TreeNode*> st; if (root == NULL) { return res; } TreeNode *cur = root; while (cur!=NULL || !st.empty()) { if (cur != NULL) { if (cur) st.push(cur); cur = cur->left; } else { cur = st.top(); st.pop(); res.push_back(cur->val); cur = cur->right; } } return res; } }; 后序遍历先序遍历是中左右,后续遍历是左右中,那么只需要调整一下先序遍历的代码顺序,就变成中右左的遍历顺序,然后在反转result数组,输出的结果顺序就是左右中了。后序遍历的代码如下所示:class Solution { public: vector<int> postorderTraversal(TreeNode* root) { vector<int> res; stack<TreeNode*> st; if (root == NULL) { return res; } st.push(root); while (!st.empty()) { TreeNode *cur = st.top(); st.pop(); if (cur->left) st.push(cur->left); if (cur->right) st.push(cur->right); res.push_back(cur->val); } reverse(res.begin(), res.end()); return res; } }; 统一的迭代遍历法参考https://programmercarl.com/%E4%BA%8C%E5%8F%89%E6%A0%91%E7%9A%84%E7%BB%9F%E4%B8%80%E8%BF%AD%E4%BB%A3%E6%B3%95.html 每次在待处理节点入栈后,加入一个NULL节点作为标记,之后在遇到NULL节点时处理栈中的下一个节点。需要注意的是,这种方法效率不高,节点可能会多次入栈。层序遍历// 迭代遍历,BFS基于队列 class Solution { public: vector<vector<int>> levelOrder(TreeNode* root) { vector<vector<int>> res; queue<TreeNode*> q; if (root == NULL) { return res; } q.push(root); while (!q.empty()) { int size =q.size(); vector<int> layer; for (int i = 0; i < size; ++i) { TreeNode *cur = q.front(); q.pop(); layer.push_back(cur->val); if (cur->left) q.push(cur->left); if (cur->right) q.push(cur->right); } res.push_back(layer); } return res; } }; // 递归,DFS class Solution { public: vector<vector<int>> levelOrder(TreeNode* root) { vector<vector<int>> res; queue<TreeNode*> q; if (root == NULL) { return res; } order(0, root, res); return res; } // DFS, 递归 void order(int depth, TreeNode *cur, vector<vector<int>> &res) { if (cur == NULL) return; if (res.size() == depth) res.push_back(vector<int>()); res[depth].push_back(cur->val); order(depth + 1, cur->left, res); order(depth + 1, cur->right, res); } }; -
LeetCode刷题 - 滑动窗口最大值 参考链接:https://programmercarl.com/0239.%E6%BB%91%E5%8A%A8%E7%AA%97%E5%8F%A3%E6%9C%80%E5%A4%A7%E5%80%BC.htmlleetcode题目链接:https://leetcode.cn/problems/sliding-window-maximum/给你一个整数数组 nums,有一个大小为 k 的滑动窗口从数组的最左侧移动到数组的最右侧。你只可以看到在滑动窗口内的 k 个数字。滑动窗口每次只向右移动一位。返回滑动窗口中的最大值 。示例 1:输入:nums = [1,3,-1,-3,5,3,6,7], k = 3输出:[3,3,5,5,6,7]解释:滑动窗口的位置最大值[1 3 -1] -3 5 3 6 731 [3 -1 -3] 5 3 6 731 3 [-1 -3 5] 3 6 751 3 -1 [-3 5 3] 6 751 3 -1 -3 [5 3 6] 761 3 -1 -3 5 [3 6 7]7示例 2: 输入:nums = [1], k = 1 输出:[1] 方法1:单调队列法使用一个数据结构,每次滑动窗口时添加一个元素,删除一个元素,同时可以从队列头部获取想要的当前窗口内的最大值。这种数据结构就是单调队列,单调队列的pop和push操作应该遵循以下原则:pop(value):如果窗口移除的元素value等于单调队列的出口元素,那么弹出元素,否则不需要任何操作;push(value):如果push的元素value大于入口元素的值,那么将队列入口的元素弹出,直到push元素的数值小于等于队列入口元素的数值为止。基于如上规则,每次窗口移动后,队列头部元素就是当前窗口的最大值。class MyQueue { //单调队列(从大到小) public: deque<int> que; // 使用deque来实现单调队列 // 每次弹出的时候,比较当前要弹出的数值是否等于队列出口元素的数值,如果相等则弹出。 // 同时pop之前判断队列当前是否为空。 void pop(int value) { if (!que.empty() && value == que.front()) { que.pop_front(); } } // 如果push的数值大于入口元素的数值,那么就将队列后端的数值弹出,直到push的数值小于等于队列入口元素的数值为止。 // 这样就保持了队列里的数值是单调从大到小的了。 void push(int value) { while (!que.empty() && value > que.back()) { que.pop_back(); } que.push_back(value); } // 查询当前队列里的最大值 直接返回队列前端也就是front就可以了。 int front() { return que.front(); } }; 方法2:优先级队列使用大顶堆,每次移动窗口时,将新的元素加入堆中,此时需要移除堆中不在窗口内的元素。为了记录堆中元素是否在窗口中,需要记录堆中元素在数组中的索引。在每次获取当前窗口内最大值之前,将堆顶的索引不在当前窗口内的元素移除。具体的实现方式如下:class Solution { struct Node { int num; int idx; Node(int n, int i) : num(n), idx(i) {} bool operator < (const Node& b) const { return this->num != b.num ? (this->num < b.num) : (this->idx < b.idx); } }; public: vector<int> maxSlidingWindow(vector<int>& nums, int k) { priority_queue<Node> pq; vector<int> res; for (int i = 0; i < nums.size(); ++i) { pq.push(Node(nums[i], i)); if (i >= k-1) { while (pq.top().idx <= i - k) { pq.pop(); } res.push_back(pq.top().num); } } return res; } };
-
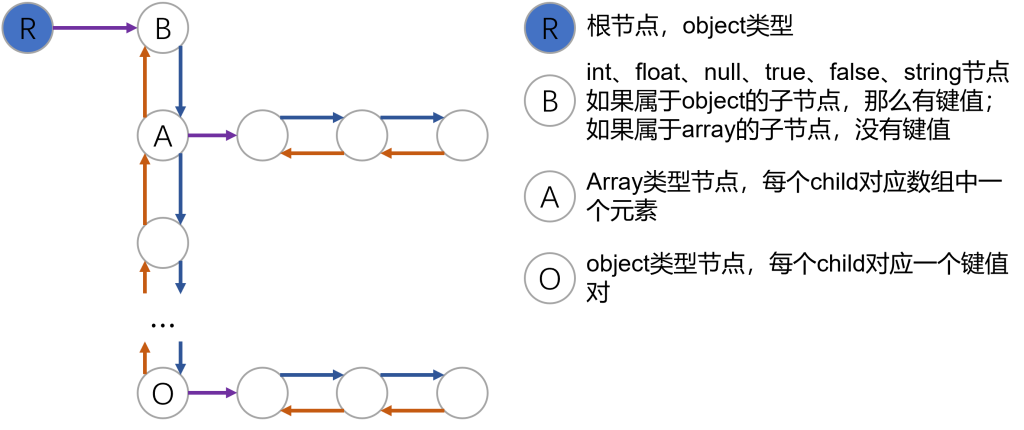
LJson LJSon A C++ library for json parse/creation/update package地址:https://github.com/lishengxie/LJson 开发原因最近在复习C++相关的知识,想要通过一个项目来巩固C++和算法的一些相关知识,但是网上推荐的相关C++项目大多比较复杂,很难下手。刚好最近实验室项目中频繁使用json文件,想到是否可以使用C++来实现一个json的解析库,在github上搜索后看到了一些现有的json仓库,初步了解后开始进行实现。参考仓库 https://github.com/510850111/cJSON/tree/master,在这个项目中学习了json对象的表示以及如何操作json对象; https://github.com/ACking-you/MyUtil/tree/master/json-parser,在这个项目中学习了如何从json字符串中解析数据,服用了部分解析json字符串的代码; https://github.com/nlohmann/json,著名的json处理库,从中学习了如何使用初始化列表来实现类Python的方式创建和更新json对象。 json文件格式这里只做简单介绍,具体的格式可以参考json官网http://www.json.org。json主要基于两种结构,分别是“键值对集合”和“值的有序列表”,前者可以看做字典或哈希表,后者可以看做数组。 1. 对象是无序的键值对集合,一个对象被包含在{}中,每个键值对的格式为key:value,其中key是字符串,value可以是字符串、布尔类型(true/false)、null、数值(整数或浮点数)、对象、数组;键值对之间使用,分隔,对象应该使用key索引对应的值; 2. 数组是值的有序集合,包含在[]中,值可以是前面提到的字符串、布尔类型(true/false)、null、数值(整数或浮点数)、对象、数组,值之间使用,分隔;通过使用对象、数组以及支持两者之间的嵌套,json可以支持复杂的数据格式定义和传递。使用数据结构表示json对象前面提到了json文件的格式,一种很自然的表示json对象的方式应该是使用字典表示对象,字典的值本身也可以是一个json对象,有一些json解析库中使用了这种方式,可以参考Python中json库对json文件的读写。我们使用了另外一种方式,即使用树形结构来表示整个json对象,如下图所示: 对应的C++定义如下,对象中的每个键值对以及数组中的每个值都使用一个JsonObject对象来表示,整个对象/数组的键值对/值使用双向链表进行表示,遍历整个双向链表即可以遍历整个json对象或数组。enum JsonType { T_FALSE=0, T_TRUE, T_NULL, T_INT, T_FLOAT, T_STRING, T_ARRAY, T_OBJECT }; class JsonObject { /* next和prev分别指向前一个对象和后一个对象 */ JsonObject *next, *prev; /* Object和Array类型对象需要设置child指针 */ JsonObject *child; /* Object的类型 */ JsonType type; /* String对象的值 */ char *valueString; /* 整数对象的值 */ int valueInt; /* 浮点数的值 */ double valueDouble; /* 键值对的键 */ char *key; } 以上图为例,假设有如下的json对象{ "name":"runoob", "alexa":10000, "sites": { "site1":"www.runoob.com", "site2":"m.runoob.com", "site3":"c.runoob.com" }, "search":[ "Google", "Runoob", "Taobao" ] } 那么对应到上面的树形结构应该为(以下提到的变量都是JsonObject类型),首先有一个root表示整个json对象,root->child对应对象内键值对的双向链表,root->child对应"name":"runoob",root->child->next对应"alexa":10000,以此类推。对于双向链表中的第四个节点node4,节点类型为数组,node4->child对应数组内值的双向链表,node4->child为"Google",node4->child->next为Runoob,以此类推。第三个节点的对象也使用类似的方式表示。方法设计根据以上的数据结构,我们可以表示整个json对象,那么接下来就是对整个json对象的操作,应该包含两部分: 从外部字符串解析出json数据对象; 创建json对象并导出。 对于json对象,这里又进一步划分为了“增、删、改、查”四个部分,接下来分别对这四个部分的设计做一下介绍。解析Json对象这里参考了https://github.com/ACking-you/MyUtil/tree/master/json-parser中的解析方式,大致的实现思路为跳过给定字符串中的空白字符和注释,每次对于不同的字符解析出对应的对象。这里使用了C++标准库string中解析整数和浮点数的方法。JsonObject* JsonParser::parse() { char token = get_next_token(); if (token == 'n') { return parseNULL(); } if (token == 't' || token == 'f') { return parseBool(); } if (token == '-' || std::isdigit(token)) { return parseNumber(); } if (token == '\"') { return parseString(); } if (token == '[') { return parseArray(); } if (token == '{') { return parseObject(); } throw std::logic_error("unexpected character in parsing json."); } 添加json节点添加json节点应该是将给定的json节点添加到一个对象或数组中,对于添加到对象中,还需要同时提供键值对的key。添加的方法比较简单,在当前调用的JsonObject的child对应的双向链表中将给定的JsonObject对象插入,对于插入到对象中的情况还需要设置key。这里使用尾插法,即将新加入的节点插入到双向链表的尾部,方便检索。插入对象的实现方式如下所示,插入数组的实现类似。void JsonObject::addItem(const char* iKey, JsonObject* item) { if(item == nullptr){ return; } if (this->type != T_OBJECT) { throw std::logic_error("must be json object to add key-value pair"); } // set key for item char* out = new char[strlen(iKey) + 1]; strcpy(out, iKey); item->key = out; // no child yet if (this->child == nullptr) { this->child = item; } else { // 尾插法, 检索更快 JsonObject* pChild = this->child; while (pChild!= nullptr && pChild->next!=nullptr){ pChild = pChild->next; } pChild->next = item; item->prev = pChild; } } 删除json节点删除节点和增加节点相反,给定key从对应的对象中或给定index从给定的数组中删除对应的节点,同样是在数组中删除相应的节点,需要注意的是对于删除的节点需要及时释放相应的内存。释放内存被实现成了JsonObject类的静态方法,通过递归的方式释放,如下所示:void JsonObject::deleteNode(JsonObject *node) { JsonObject *nextNode; JsonObject *curNode = node; while (curNode != nullptr) { nextNode = curNode->next; if (curNode->child) { deleteNode(curNode->child); } if (curNode->valueString) { delete [](curNode->valueString); curNode->valueString = nullptr; } if (curNode->key) { delete [](curNode->key); curNode->key = nullptr; } delete curNode; curNode = nextNode; } } 查找json节点给定key从对应的对象中或给定index从给定的数组中查找对应的节点,这里通过重载[]运算符实现,下面给出了给定key查找出对应值的实现,在key不存在的情况下会创建出一个null对象并返回。对于给定index查找数组的实现,在index超出数组索引范围的情况下会返回一个全局的查找标志表示返回失败,后续可以实现为添加对应数量的null节点。JsonObject& JsonObject::operator[] (const char* iKey) { JsonObject *cur = this->child; while (cur != nullptr) { if(strcmp(iKey, cur->key) == 0) { return *cur; } cur = cur->next; } JsonObject *object = JsonObject::createNULL(); this->addItem(iKey, object); return *object; } 更改json节点对于修改json节点,通过重载=运算符的方式加以实现,前面几个函数对数字、字符串、布尔值和空值几种基本数据类型实现了重载,最后一个函数提供通过initializer_list的方式来更新JsonObject。JsonObject& operator=(int number); JsonObject& operator=(double number); JsonObject& operator=(const char* strValue); JsonObject& operator=(bool boolValue); JsonObject& operator=(std::nullptr_t nullValue); JsonObject& operator=(std::initializer_list<InitType> initList); 对于前几个函数,实现的方式为修改节点的类型,如果被修改的节点是对象或数组类型,那么使用deleteNode方法删除其child指向的双向链表,以赋值为整数为例,其函数实现如下所示:JsonObject& JsonObject::operator=(int number) { if (*this == LJson::npos) { std::cerr << "can not assign to non-existent object\n"; return *this; } if (this->type == T_OBJECT || this->type == T_ARRAY) { JsonObject::deleteNode(this->child); this->child = nullptr; } this->type = T_INT; this->valueInt = number; return *this; } 对于使用initializer_list来更新JsonObject的例子,通过自定义一个InitType结构体来加以支持,InitType会将初始化列表转换成一个数组类型的JsonObject,随后我们检查整个数组并进行数组到对象的转换。判断一个数组是否是对象的标准如下: 1. 数组中的每个值都是一个数组; 2. 数组中每个值对应的子数组长度都为2; 3. 数组中每个值对应的子数组的第一个元素都是字符串类型。满足以上三个条件的数组应该被转换成一个对象,转换过程递归进行,具体实现可以参考github中的代码。其他工具函数提供了一个JsonParser工具类用于解析json字符串,提供了一个Json类来将JsonObject和JsonParser的功能进行封装,方便使用。此外,还提供了json对象转换为字符串的格式化方法。待实现 [ ] 检查实现中的动态内存分配和释放,避免造成内存泄漏; [ ] 有一些冗余代码,后续考虑使用模版函数进行替换; [ ] 接口目前有些混乱,另外异常情况目前没有很好地处理; [ ] 添加HashTable用于记录键->JsonObject指针,避免每次检索时都需要遍历,提高检索速度。
-
GDB调试学习 前言使用linux进行systemc的开发时经常出现core dump的文件,对于较大的项目vscode无法很快地进行debug,clion对makefile的支持不是很好,此时想到使用gdb进行调试并学习了一些基本的操作。以下的内容主要参考这篇博客和gdb debug的参考文档。参考资料: 1. https://www.yanbinghu.com/2019/04/20/41283.html 2. Debugging with GDB启动调试GDB需要一个带有调试信息的可执行文件进行调试,因此编译过程中出现的错误无法使用GDB进行排除。通常对于C或者C++程序来说,在编译时加上-g参数可以保留调试信息,否则不能使用GDB进行调试。使用cmake时,可以在CMakeLists.txt文件中添加以下指令以支持GDB调试。SET(CMAKE_BUILD_TYPE "Debug") SET(CMAKE_CXX_FLAGS_DEBUG "$ENV{CXXFLAGS} -O0 -Wall -g2 -ggdb") SET(CMAKE_CXX_FLAGS_RELEASE "$ENV{CXXFLAGS} -O3 -Wall") 如果程序不是自己编译的,那么如何判断文件中是否带有调试信息呢,这篇博客中给出了几种调试的方法。 1. 使用gdb$ gdb main Reading symbols from main... 如果提示no debugging symbols found, 那么不可以使用gdb调试该可执行文件。 2. readelf# main是可执行文件名称 $ readelf -S main | grep debug file查看strip状况 $ file main 如果输出内容为xxx stripped, 那么说明该文件的调试信息已经被去除,不能使用gdb调试。但是not stripped的情况不能说明该文件可以被调试。启动调试无参数程序$ gdb main (gdb) run 输入run命令即可运行程序。有参数程序$ gdb main # world对应参数 (gdb) run world # 使用set args (gdb) set args world (gdb) run 结束调试使用quit指令。调试core文件本文最开始提到进行C++开发时经常遇到core dump的问题,这种情况下需要定位到具体的core dump的位置,目前了解到两种方法,一种是使用backward-cpp插件,在linux系统上可以打印出详细的报错信息,具体可以参考博客https://zhuanlan.zhihu.com/p/397148839;另一种就是利用gdb进行调试。当程序core dump时会产生core文件,可以很大程度上帮助我们定位问题,但是前提是系统没有限制core文件的产生,使用ulimit -c查看$ ulimit -c 0 如果结果是0,那么core dump后也不会有core文件留下,此时需要进行额外的设置ulimit -c unlimied #表示不限制core文件大小 ulimit -c 10 #设置最大大小,单位为块,一块默认为512字节 调试core文件使用如下命令gdb 程序文件名 core文件名 断点设置 & 变量查看关于断点设置和变量查看的相关内容可以查看这篇博客https://www.yanbinghu.com/2019/04/20/41283.html,后续有时间的话会对相关内容加以整理。目前调试主要还是借助IDE,对于一些core dump或者没有IDE的情况,gdb的调试将不可或缺,因此这里简单学习后加以记录。
-
Cmake常用指令学习 参考教程 Cmake Cookbook:https://www.bookstack.cn/read/CMake-Cookbook/README.md Cmake官方文档:https://cmake.org/cmake/help/latest/guide/tutorial/index.html Cmake入门实战: https://www.hahack.com/codes/cmake/ CMake 生成静态库与动态库:https://blog.csdn.net/zhiyuan2021/article/details/129032343 Cmake介绍Cmake是一种支持跨平台编译的工具,允许通过配置独立的配置文件CMakeList.txt来定制编译流程,随后在不同的平台上进一步生成本地的Makefile和工程文件(Linux平台的Makefile和Windows平台的Visual Studio工程等)。在linux平台下使用Cmake编译程序的主要流程是: 1. 编写CMakeLists.txt; 2. 执行cmake PATH生成Makefile; 3. 执行make编译生成可执行程序或动态/静态链接库。Cmake使用基础案例# CMake 最低版本号要求 cmake_minimum_required (VERSION 2.8) # 项目信息 project (project_name) # 指定生成目标 add_executable(project_name main.cc) CMakeLists.txt的语法由命令、注释和空格组成,命令不区分大小写,#后面的内容是注释。命令由命令名称、小括号和参数组成,参数之间使用空格进行间隔。上面的示例中CmakeLists.txt中使用了几个常用的命令,依次是 1. cmake_minimum_required:指定运行当前配置文件需要的最低的Cmake版本; 2. project:指定项目名称 3. add_executable:将main.cc源文件编译成名为project_name的可执行文件。实际使用中可能有多个源文件,逐个添加源文件是一件非常麻烦的事情,可以使用aux_source_directory命令来获取指定目录下的所有源文件,并将结果存到指定变量名中,使用示例如下:# 查找当前目录下的所有源文件 # 并将名称保存到 DIR_SRCS 变量 aux_source_directory(. DIR_SRCS) # 指定生成目标 add_executable(Demo ${DIR_SRCS}) Cmake生成动态和静态链接库静态和动态链接库的主要目的是为了提供接口供其他程序调用,两者的主要区别在于: 1. 静态链接库的拓展名通常为.a或.lib,在编译时会直接整合到目标程序中,编译成功的可执行文件可以独立运行(不再需要静态库); 2. 动态链接库的拓展名通常为.so或.dll,在编译时不会放到目标程序中,可执行文件无法离开动态链接库单独执行。Cmake用于生成动态和静态链接库的命令为# 动态链接库 add_library(project_name SHARED ${SRC_FILE}) # 静态链接库 add_library(project_name STATIC ${SRC_FILE}) Cmake引用外部库文件Cmake中另外一个常用的使用场景是使用外部库,对于外部库,我们通常需要进行两步操作,即引入头文件和添加链接库,具体示例如下所示:# 引入头文件所在路径 include_directories{include_path} # 添加链接库 target_link_libraries(project_name lib_name) 其他常见的Cmkae命令# 设置C++标准为C++14 set(CMAKE_CXX_STANDARD 14)