LJSon
- A C++ library for json parse/creation/update
- package地址:https://github.com/lishengxie/LJson
开发原因
最近在复习C++相关的知识,想要通过一个项目来巩固C++和算法的一些相关知识,但是网上推荐的相关C++项目大多比较复杂,很难下手。刚好最近实验室项目中频繁使用json文件,想到是否可以使用C++来实现一个json的解析库,在github上搜索后看到了一些现有的json仓库,初步了解后开始进行实现。
参考仓库
- https://github.com/510850111/cJSON/tree/master,在这个项目中学习了json对象的表示以及如何操作json对象;
- https://github.com/ACking-you/MyUtil/tree/master/json-parser,在这个项目中学习了如何从json字符串中解析数据,服用了部分解析json字符串的代码;
- https://github.com/nlohmann/json,著名的json处理库,从中学习了如何使用初始化列表来实现类Python的方式创建和更新json对象。
json文件格式
这里只做简单介绍,具体的格式可以参考json官网http://www.json.org。
json主要基于两种结构,分别是“键值对集合”和“值的有序列表”,前者可以看做字典或哈希表,后者可以看做数组。
1. 对象是无序的键值对集合,一个对象被包含在{}中,每个键值对的格式为key:value,其中key是字符串,value可以是字符串、布尔类型(true/false)、null、数值(整数或浮点数)、对象、数组;键值对之间使用,分隔,对象应该使用key索引对应的值;
2. 数组是值的有序集合,包含在[]中,值可以是前面提到的字符串、布尔类型(true/false)、null、数值(整数或浮点数)、对象、数组,值之间使用,分隔;
通过使用对象、数组以及支持两者之间的嵌套,json可以支持复杂的数据格式定义和传递。
使用数据结构表示json对象
前面提到了json文件的格式,一种很自然的表示json对象的方式应该是使用字典表示对象,字典的值本身也可以是一个json对象,有一些json解析库中使用了这种方式,可以参考Python中json库对json文件的读写。我们使用了另外一种方式,即使用树形结构来表示整个json对象,如下图所示:
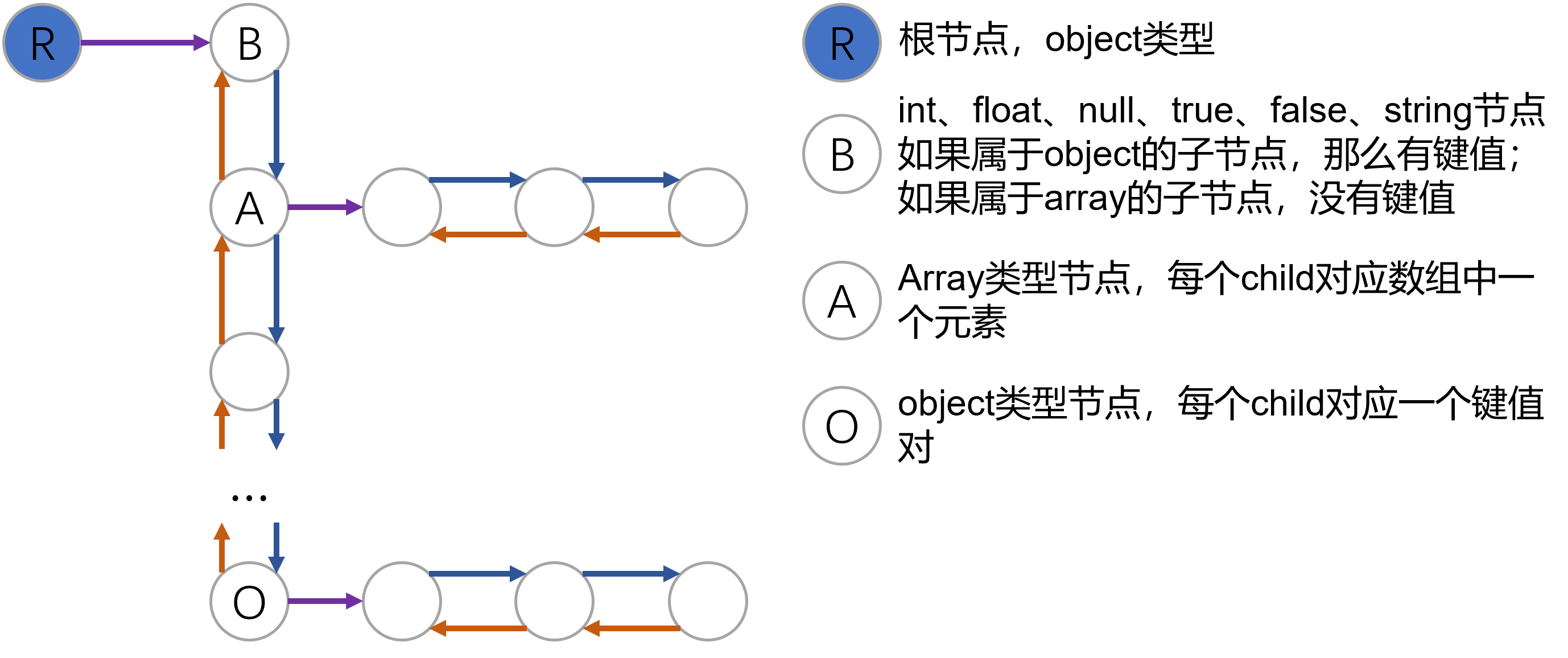
对应的C++定义如下,对象中的每个键值对以及数组中的每个值都使用一个JsonObject对象来表示,整个对象/数组的键值对/值使用双向链表进行表示,遍历整个双向链表即可以遍历整个json对象或数组。
enum JsonType {
T_FALSE=0, T_TRUE, T_NULL, T_INT, T_FLOAT, T_STRING, T_ARRAY, T_OBJECT
};
class JsonObject {
/* next和prev分别指向前一个对象和后一个对象 */
JsonObject *next, *prev;
/* Object和Array类型对象需要设置child指针 */
JsonObject *child;
/* Object的类型 */
JsonType type;
/* String对象的值 */
char *valueString;
/* 整数对象的值 */
int valueInt;
/* 浮点数的值 */
double valueDouble;
/* 键值对的键 */
char *key;
}
以上图为例,假设有如下的json对象
{
"name":"runoob",
"alexa":10000,
"sites": {
"site1":"www.runoob.com",
"site2":"m.runoob.com",
"site3":"c.runoob.com"
},
"search":[ "Google", "Runoob", "Taobao" ]
}
那么对应到上面的树形结构应该为(以下提到的变量都是JsonObject类型),首先有一个root表示整个json对象,root->child对应对象内键值对的双向链表,root->child对应"name":"runoob",root->child->next对应"alexa":10000,以此类推。对于双向链表中的第四个节点node4,节点类型为数组,node4->child对应数组内值的双向链表,node4->child为"Google",node4->child->next为Runoob,以此类推。第三个节点的对象也使用类似的方式表示。
方法设计
根据以上的数据结构,我们可以表示整个json对象,那么接下来就是对整个json对象的操作,应该包含两部分:
- 从外部字符串解析出json数据对象;
- 创建json对象并导出。
对于json对象,这里又进一步划分为了“增、删、改、查”四个部分,接下来分别对这四个部分的设计做一下介绍。
解析Json对象
这里参考了https://github.com/ACking-you/MyUtil/tree/master/json-parser中的解析方式,大致的实现思路为跳过给定字符串中的空白字符和注释,每次对于不同的字符解析出对应的对象。这里使用了C++标准库string中解析整数和浮点数的方法。
JsonObject* JsonParser::parse() {
char token = get_next_token();
if (token == 'n') {
return parseNULL();
}
if (token == 't' || token == 'f') {
return parseBool();
}
if (token == '-' || std::isdigit(token)) {
return parseNumber();
}
if (token == '\"') {
return parseString();
}
if (token == '[') {
return parseArray();
}
if (token == '{') {
return parseObject();
}
throw std::logic_error("unexpected character in parsing json.");
}
添加json节点
添加json节点应该是将给定的json节点添加到一个对象或数组中,对于添加到对象中,还需要同时提供键值对的key。添加的方法比较简单,在当前调用的JsonObject的child对应的双向链表中将给定的JsonObject对象插入,对于插入到对象中的情况还需要设置key。这里使用尾插法,即将新加入的节点插入到双向链表的尾部,方便检索。插入对象的实现方式如下所示,插入数组的实现类似。
void JsonObject::addItem(const char* iKey, JsonObject* item) {
if(item == nullptr){
return;
}
if (this->type != T_OBJECT) {
throw std::logic_error("must be json object to add key-value pair");
}
// set key for item
char* out = new char[strlen(iKey) + 1];
strcpy(out, iKey);
item->key = out;
// no child yet
if (this->child == nullptr) {
this->child = item;
} else {
// 尾插法, 检索更快
JsonObject* pChild = this->child;
while (pChild!= nullptr && pChild->next!=nullptr){
pChild = pChild->next;
}
pChild->next = item;
item->prev = pChild;
}
}
删除json节点
删除节点和增加节点相反,给定key从对应的对象中或给定index从给定的数组中删除对应的节点,同样是在数组中删除相应的节点,需要注意的是对于删除的节点需要及时释放相应的内存。释放内存被实现成了JsonObject类的静态方法,通过递归的方式释放,如下所示:
void JsonObject::deleteNode(JsonObject *node) {
JsonObject *nextNode;
JsonObject *curNode = node;
while (curNode != nullptr) {
nextNode = curNode->next;
if (curNode->child) {
deleteNode(curNode->child);
}
if (curNode->valueString) {
delete [](curNode->valueString);
curNode->valueString = nullptr;
}
if (curNode->key) {
delete [](curNode->key);
curNode->key = nullptr;
}
delete curNode;
curNode = nextNode;
}
}
查找json节点
给定key从对应的对象中或给定index从给定的数组中查找对应的节点,这里通过重载[]运算符实现,下面给出了给定key查找出对应值的实现,在key不存在的情况下会创建出一个null对象并返回。对于给定index查找数组的实现,在index超出数组索引范围的情况下会返回一个全局的查找标志表示返回失败,后续可以实现为添加对应数量的null节点。
JsonObject& JsonObject::operator[] (const char* iKey) {
JsonObject *cur = this->child;
while (cur != nullptr) {
if(strcmp(iKey, cur->key) == 0) {
return *cur;
}
cur = cur->next;
}
JsonObject *object = JsonObject::createNULL();
this->addItem(iKey, object);
return *object;
}
更改json节点
对于修改json节点,通过重载=运算符的方式加以实现,前面几个函数对数字、字符串、布尔值和空值几种基本数据类型实现了重载,最后一个函数提供通过initializer_list的方式来更新JsonObject。
JsonObject& operator=(int number);
JsonObject& operator=(double number);
JsonObject& operator=(const char* strValue);
JsonObject& operator=(bool boolValue);
JsonObject& operator=(std::nullptr_t nullValue);
JsonObject& operator=(std::initializer_list<InitType> initList);
对于前几个函数,实现的方式为修改节点的类型,如果被修改的节点是对象或数组类型,那么使用deleteNode方法删除其child指向的双向链表,以赋值为整数为例,其函数实现如下所示:
JsonObject& JsonObject::operator=(int number) {
if (*this == LJson::npos) {
std::cerr << "can not assign to non-existent object\n";
return *this;
}
if (this->type == T_OBJECT || this->type == T_ARRAY) {
JsonObject::deleteNode(this->child);
this->child = nullptr;
}
this->type = T_INT;
this->valueInt = number;
return *this;
}
对于使用initializer_list来更新JsonObject的例子,通过自定义一个InitType结构体来加以支持,InitType会将初始化列表转换成一个数组类型的JsonObject,随后我们检查整个数组并进行数组到对象的转换。判断一个数组是否是对象的标准如下:
1. 数组中的每个值都是一个数组;
2. 数组中每个值对应的子数组长度都为2;
3. 数组中每个值对应的子数组的第一个元素都是字符串类型。
满足以上三个条件的数组应该被转换成一个对象,转换过程递归进行,具体实现可以参考github中的代码。
其他工具函数
提供了一个JsonParser工具类用于解析json字符串,提供了一个Json类来将JsonObject和JsonParser的功能进行封装,方便使用。此外,还提供了json对象转换为字符串的格式化方法。
待实现
- [ ] 检查实现中的动态内存分配和释放,避免造成内存泄漏;
- [ ] 有一些冗余代码,后续考虑使用模版函数进行替换;
- [ ] 接口目前有些混乱,另外异常情况目前没有很好地处理;
- [ ] 添加HashTable用于记录键->JsonObject指针,避免每次检索时都需要遍历,提高检索速度。