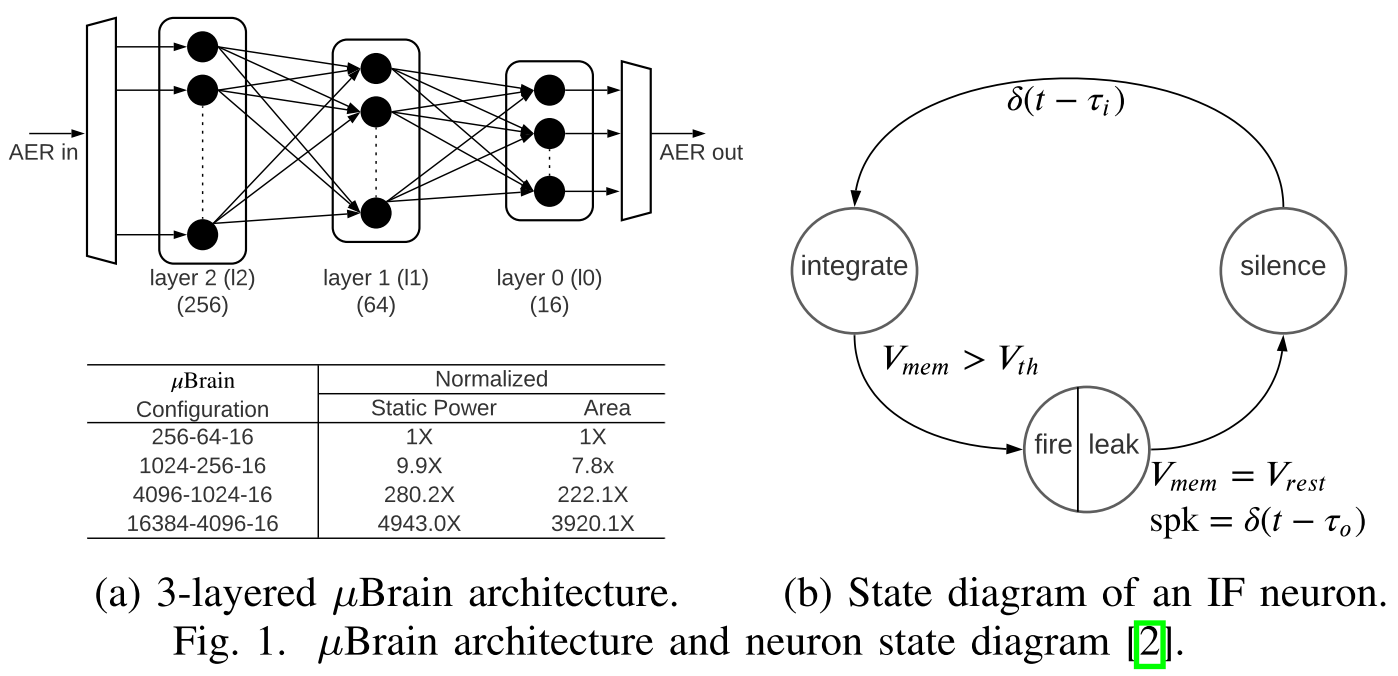
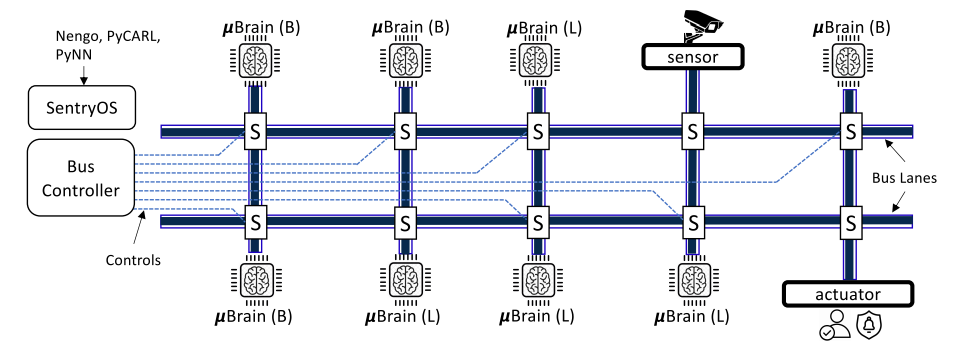
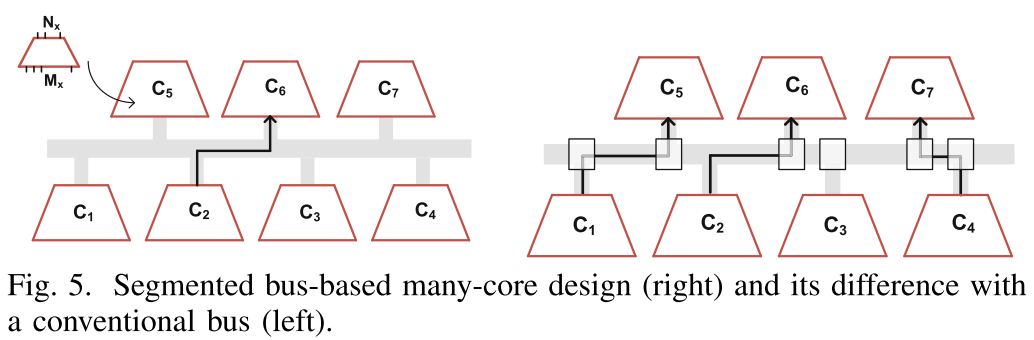
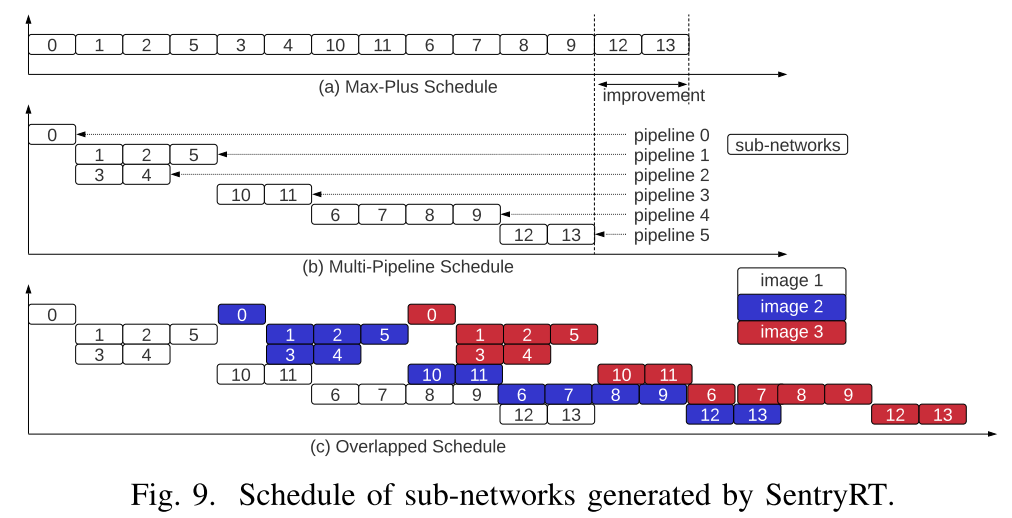
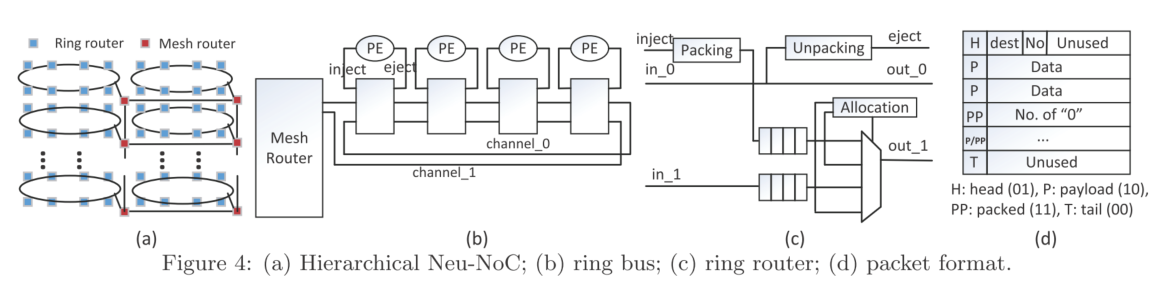
提出了一种环形+Mesh结合的NoC结构,同时基于该结构提出了相应的映射算法、广播协议和基于权重稀疏性的通信量减少方案,相较于现有的2D-Mesh的方法有效地减少了通信的延迟和能量消耗。
Motivation
- 相邻层之间通信频繁,导致NoC中大部分的通信量分布在较少的通信信道上;
- 全连接层中前一层的一个神经元给下一层的所有神经元发送的数据本质上是一样的,因此传输的数据包中有相当一部分是重复的数据。
Neu-NoC结构介绍
- Mesh+ring结合,同一层中的神经元映射到一个ring中来减少数据的搬运,ring中提供两条信道,分别用于接收和发送数据以提高信息的传输速度;
- ring中使用ring路由,根据上图c)可以看到ring路由包含相应的2选1多选器、缓存和打包解包模块,同时提供分配模块用于仲裁(例如,正在传输的包比刚输入的包优先级更高)
NN-aware Mapping
- 将神经元映射到具体的物理计算核心上,使得神经元之间的通信跳数最小
- 本质是贪婪算法,寻找局部最优的映射方案

packet广播
在packet的header中添加一段标志位用于支持广播协议,标志位长度和Mesh路由的总数目相同;如1->7->9->10中分别广播到9和10,因此将9和10的标志位置为1,经过9后,9的标志位被置为0随后继续传递给10;
稀疏感知的通信量减少
- 利用神经网络中特征图的稀疏性,提出了all-zero flit,该flit中使用特殊标志位,同时在payload中指出有多少个连续的全0包。根据这种方式将多个全0的数据包压缩成一个,由Mesh和ring之间的路由提供支持。
实验
- 针对全连接层
- 基于Booksim仿真器:https://github.com/booksim/booksim2
- ring中的局部延迟和全局通信跳数随着同一个ring中支持的PE数量增加呈现出先增后减的趋势;
- 实验中发现通过将低于某个阈值的激活值置为0,提高特征图的稀疏性之后,精度不会受到严重的影响,因此可以在提高稀疏性和保持精度之间做一定的权衡;
- 提出的方法可以获得较好的性能,相较于普通的2D-Mesh的方法可以降低23.2%的包传输延迟和31.1%的能量消耗。
思考:
- ring加Mesh结合的方法比较有特点;
- 能否直接在现有的2D-Mesh之间实现相应的映射方法,将同一层的神经元映射到相邻的PE上,但是相较于顺序方式需要一定的性能提升?
- 多播和0数据压缩的方式可以参考,尤其是对于SNN可以在时间维度上进行压缩,减少传输的延迟。